图像分类
最近用到了很多图像分类算法,就想着总结下,也方便日后查询
正文
图像分类,即根据图像信息,将图像分为提前设定好的几种类型。
如将图像分为:猫、狗、鸟等。
也有较为经典的早期手写字符识别:分为0~9 十类字符。
虽然都属于图像分类,但从问题本身上依旧有所区别
从任务上看图像分类
- 跨物种语义级别的图像分类
所谓跨物种语义级别的图像分类,它是在不同物种的层次上识别不同类别的对象,比较常见的包括如猫狗分类等。这样的图像分类,各个类别之间因为属于不同的物种或大类,往往具有较大的类间方差,而类内则具有较小的类内误差。 - 子类细粒度图像分类
细粒度图像分类,相对于跨物种的图像分类,级别更低一些。它往往是同一个大类中的子类的分类,如不同鸟类的分类,不同狗类的分类,不同车型的分类等。 - 实例级图像分类
如果我们要区分不同的个体,而不仅仅是物种类或者子类,那就是一个识别问题,或者说是实例级别的图像分类,最典型的任务就是人脸识别。
从方法上看图像分类
特征提取的传统算法
早期等图像分类均是基于传统的图像处理方法来提取固定的图像特征,如色彩、轮廓、纹理等。然后根据所提取的图像特征,采用模式匹配、样板匹配等方法来进行区分,从而达到图像的分类,但该类方法通常基于专家经验采用固定的卷积算子进行特征提取,所提取的特征表征能力有限从而模型的泛化性能有限。
基于机器学习的图像分类方法
机器学习是基于训练数据构建统计模型,从而使模型具有对新数据进行预测和分析的能力,该类方法通常是基于数据驱动的,具有很好的泛化性能,最初基于机器学习的图像分类方法,依旧采用一些传统图像处理方法来采集图像特征,然后将采集的特征与图像类别构建训练数据集,通过SVM、决策树、全连接神经网络等分类算法来进行训练,从而得到图像分类模型。
基于深度学习的图像分类方法
但由于提取特定的图像特征难以包含 所有的图像信息,而人工设计的特征提取方法并不一定适用,而整个图像所包含的像素点(特征值)较多,将其直接拉伸为特征向量送入分类模型会使模型过于庞大,因此提出了卷积神经网络,通过一系列卷积池化操作将图像转为较低维度的特征图然后进行分类,其中的卷积操作与传统的卷积算子不同,其卷积核的参数为训练过程中通过损失函数反向传播优化得出,因此具有很好的泛化性能。
LeNet
论文 发表时间:1998 年
以现在的眼光来看,LeNet 绝对是一个小网络,也没什么特点。但是,LeNet 是 CNN 网络结构的开山鼻祖,第一次定义了 CNN 网络结构。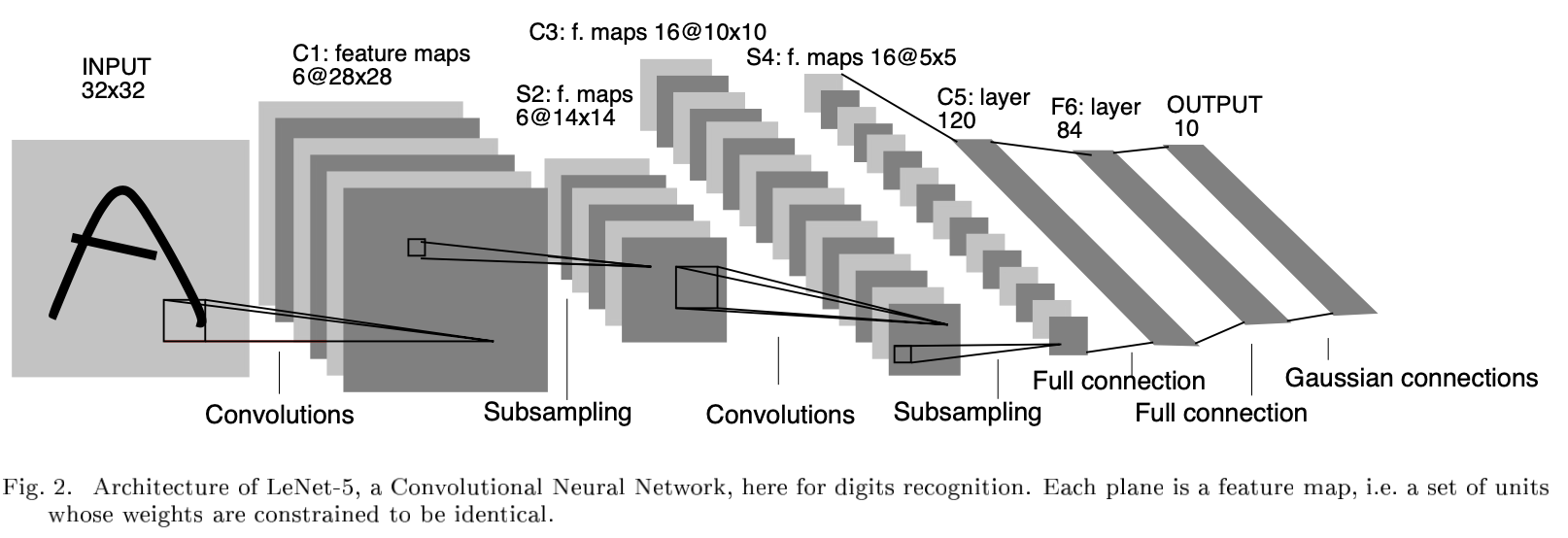
LeNet 的特点如下所示:
- 定义了卷积神经网络(Convolutional Neural Network, CNN)的基本框架:卷积层 + 池化层(Pooling Layer) + 全连接层
- 定义了卷积层(Convolution Layer),与全连接层相比,卷积层的不同之处有两点:局部连接(引进“感受野”这一概念)、权值共享(减少参数数量)
- 利用池化层进行下采样(Downsampooling),从而减少计算量
- 用 Tanh 作为非线性激活函数(现在看到的都是改进过的 LeNet 了,用 ReLU代替Tanh。相较于Sigmoid,Tanh以原点对称(zero-centered),收敛速度会快。 关于其解释,请看:谈谈激活函数以零为中心的问题)
关于全连接层,作者 Yann LeCun 曾在推特上指出:直接将特征图(Featuremap)展开输入到全连接层,会导致 CNN 仅适用于指定尺度的图像上。LeCun 认为 CNN 应该尽可能适用与各种尺度的图像上,这一点也得到许多人的认同。对于分类(Classification)问题,利用全局平均池化(Global Average Pooling, GAP)操作代替特征图的拉伸,这样 CNN 便可以处理各种尺度的图像了。而对于语义分割(Semantic Segmentation)问题,Fully Convolutional Networks for Semantic Segmentation 已经提出了一个完全没有全连接层的全卷积网络了,可以在这个问题上处理任意大小的图像。
一般来说,卷积和池化的核的宽与高相等。
卷积计算公式:$Size_out = (Size_in - Kernel_Pooling+2*Padding)/Stride+1$
池化计算公式:$Size_out = (Size_in - Kernel_Pooling)/Stride+1$
AlexNet
论文 发表时间:2012 年
2012 年,Krizhevsky 与 Hinton 推出了 AlexNet,并在当年的 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)中以超过第二名10.9个百分点的绝对优势一举夺冠,引起了许多学者对深度学习的研究,可以算是深度学习的热潮的起始标志吧。
当时的算力不如现在这样强劲,AlexNet 用的 GTX 580 也只有 3GB 的显存(这也导致其设计出双 GPU 框架,现在的许多深度学习框架都有这样的能力,不过当时只能通过手动编写底层代码,工作量可想而知),却完成了在 ImageNet 上的巨大突破,这在当时是非常轰动的,变相证明了深度学习的能力。
由于算力的不断进步,AlexNet 在许多任务显得太”小”了,很少见到它的身影。所以我认为相较于 AlexNet 的框架,作者所做的一些其他改进更有值得研究的地方。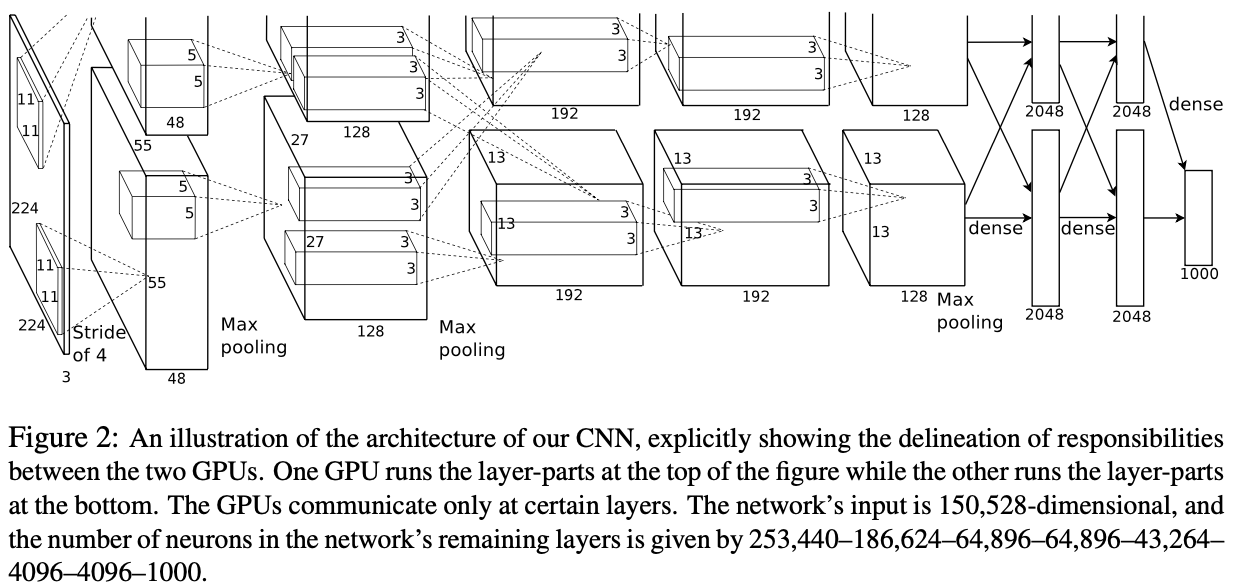
AlexNet 的特点如下所示:
- 采用双 GPU 网络结构,从而可以设计出更“大”、更“深”的网络(相较于当时的算力来说)
- 采用 ReLU 代替 Tanh,稍微解决梯度消失问题(Gradient Vanishing Problem),加快网络收敛速度。(关于常见激活函数的比较,可以看这篇:常用激活函数的比较 - 知乎)
- 提出局部相应归一化(LRN, Local Response Normalization),据作者所言,该操作能减少指标 Top-1/Top-5 Error Rate 1.4%/1.2%。(我个人不喜欢 LRN,因为我觉得它的超参数太多了,不具备很好的泛化能力。关于 Normalization 的发展历程可以看这篇:神经网络中 Normalization 的发展历程)
- 令 Pooling 操作中的 stride 小于池化核的大小,从而使相邻的池化区域存在重叠部分,这一操作称为 Overlapping Pooling。据作者所言,这一操作能减少指标 Top-1/Top-5 Error Rate 0.4%/0.3%,并且减少过拟合现象。
- 对训练数据进行随机裁剪(Random Crop),将训练图像由 256 × 256 裁剪为 224 × 224,并做随机的镜像翻转(Horizontal Reflection)。并在测试时,从图像的四个角以及中心进行裁剪,并进行镜像翻转,这样可以得到 10 个 Patch,将这些 Patch 的结果进行平均,从而得到最终预测结果。(之前在一个人脸识别比赛中,我师兄用这样的操作直接提高了4~5个点,算是一种简单的集成操作吧)
- 对训练图像做 PCA(主成分分析),利用服从 (0,0.1) 的高斯分布的随机变量对主成分进行扰动。作者指出,这一操作能减少指标 Top-1 Error Rate 1%。
- 利用 Dropout 避免网络过拟合。(我觉得这也算是集成操作的一种,因为随着模型的复杂度的提高,弱分类器也会越来越大,纯粹由弱分类器进行 Ensemble 应该不实际。最近谷歌对 Dropout 的专利貌似申请下来了,据说相关文档详细到可以作为 Dropout 的使用指南。)
PyTorch 中的 TORCHVISION.MODELS 提供基于 ImageNet 训练好的 AlexNet 模型,将其加载到显存中占了 1191 MiB(训练与测试所占显存大小依赖于实验设置,故不做讨论)。
VGG
论文 发表时间:2014 年
2014 年,Simonyan 和 Zisserman 提出了 VGG 系列模型(包括VGG-11/VGG-13/VGG-16/VGG-19),并在当年的 ImageNet Challenge 上作为分类任务第二名、定位(Localization)任务第一名的基础网络出现。对于当时而言,VGG 属于很”深“的网络,已经达到 19 层的深度(虽然同年的 GooLeNet 有22层),这是一个不小的突破,因为理论上神经网络模型的拟合能力应该是随着模型”大小“不断增加的。
虽然 VGG 的出现时间比较早,而且隔年又出现了 ResNet 这样现象级的网络模型,但是至今仍经常出现在论文中(虽然往往作为比较对象出现)。此外,VGG 的一些设置至今都在使用,所以,有必要了解一下 VGG 的网络结构。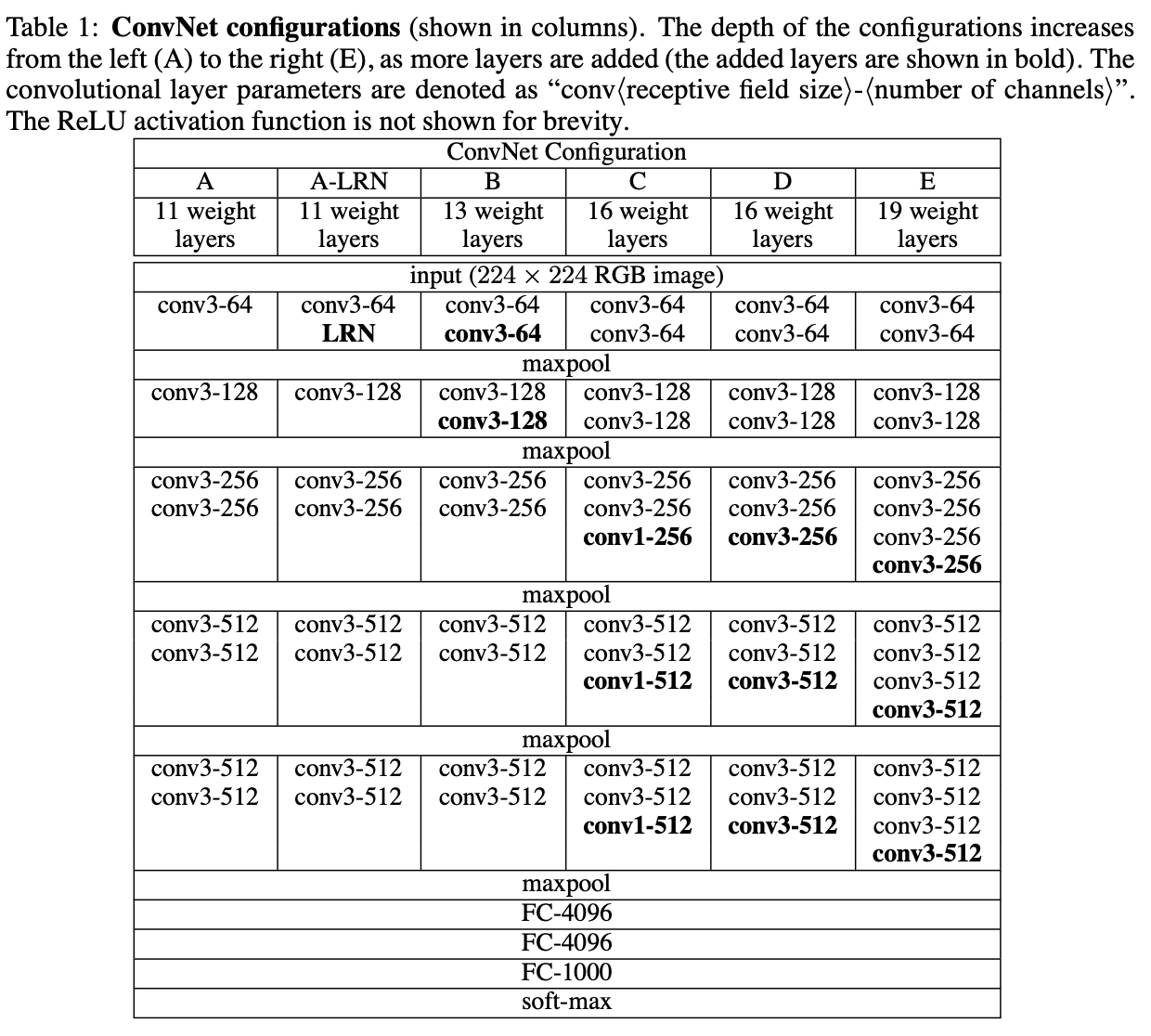
网络结构:
VGG 其实跟 AlexNet 有一定的相似之处,都是由五个卷积层与激活函数叠加的部分和三个全连接层组成,但是不同的是,VGG加“深”了前面由五个卷积层与激活函数叠加的部分,使得每部分并不是一个卷积层加一个激活函数组成,而是多个这样的组合组成一部分(有人习惯称这个为 Conv Layer Group),每个部分之间进行池化操作。
此外,VGG 与当时其他卷积神经网络不同,不采用感受野大的卷积核(如:7 × 7,5 × 5),反而采用感受野小的卷积核(3 × 3)。关于这样做的好处,作者指出有如下两点:减少网络参数量;由于参数量被大幅减小,于是可以用多个感受野小的卷积层替换掉之前一个感受野大的卷积层,从而增加网络的非线性表达能力。
从 VGG-16 开始,VGG 引进卷积核大小为 1 × 1 的卷积层(最早应该在 Network In Network 提到),使得在不影响特征图大小的情况下,增加网络的非线性表达能力。
由上图可以看出,VGG 每个“大”部分计算得到的特征图大小应该是固定的,以输入大小为 (224,244,3) 的图像举例,所计算得到的特征图大小分别为 (112,112,64),(56,56,128),(28,28,256),(14,14,512),(7,7,512)。(VGG 的最后三层全连接层太大了,尤其是第一层,大小达到了 (25088,4096) )
其他细节:
- 作者提到曾使用 LRN,但是并没有任何效果提升,反而还使得内存使用和计算时间增加。
- 在训练过程中,作者为避免随机初始化对训练带来负面影响,于是利用小的网络参数初始化大的网络参数(比如用以训练好的 VGG-11 去初始化部分 VGG-13 的网络参数)。
- 对训练图像进行预处理时,先做宽高等比缩放(原文用的词是 isotropically rescaled,即同质化缩放),使其最短边长度达到 S,接着再做随机裁剪。其中,关于 S 的设置,作者提出了两种训练方案:Single-Scale Training,Multi-Scale Training。
PyTorch 中的 TORCHVISION.MODELS 提供基于 ImageNet 训练好的 VGG-11/VGG-13/VGG-16/VGG-19 模型,以及对应使用 Batch Normalization 的版本,分别将其加载到显存中占了 1467/1477/1501/1527 MiB(训练与测试所占显存大小依赖于实验设置,故不做讨论)。
Inception Net V1 (GoogLeNet)
论文 发表时间:2014 年
2014 年,Google 提出了 Inception 网络结构,并以此构建了 GoogLeNet(之所以这样命名,是为了向LeNet致敬;此外,GoogLeNet 也经常被称为 Inception Net V1,而该论文经常被称为 Inception V1),从而在同年的 ImageNet Challenge 的分类与检测(Detection)任务上夺得第一名。
与 VGG 不同,Inception 结构虽然也倾向于加“深”网络结构,从而提高模型的表达能力,但是作者充分考虑到现实中计算资源的限制,所以对模型中局部结构进行了精心设计,并且抛弃全连接层(虽然 GoogLeNet 最后加了一层全连接层,但这是作者为了其他人能更方便的利用模型进行微调(Finetune))。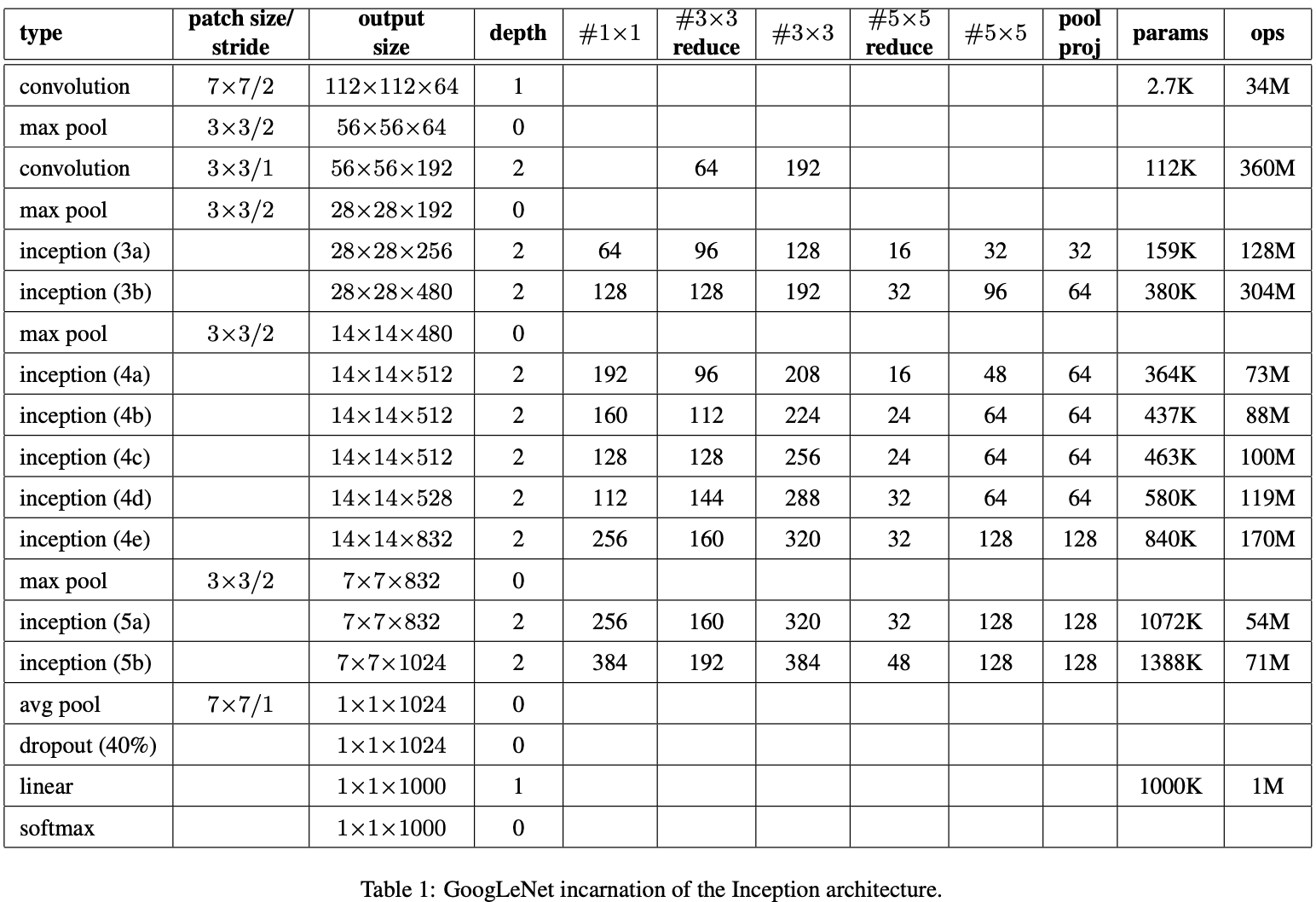
作者在文中指出,提高模型表达能力的最直接的办法就是增加模型的“大小”,而这又会导致两个问题的产生:模型越大,其网络参数也就越大,就越容易产生过拟合现象,所以就需要更大的数据集,然而大型数据集的构建成本是很高昂的;模型越大,对于计算资源的需求就越大,这在现实任务中是难以接受的。而作者认为解决这两个问题的基本方法是将全连接层,甚至是卷积层改为稀疏的网络结构。(作者还在文中指出,GoogLeNet 的参数仅有 AlexNet 的 1/12,而 AlexNet 的全连接层的参数量甚至占到了自身参数量的 90% 以上)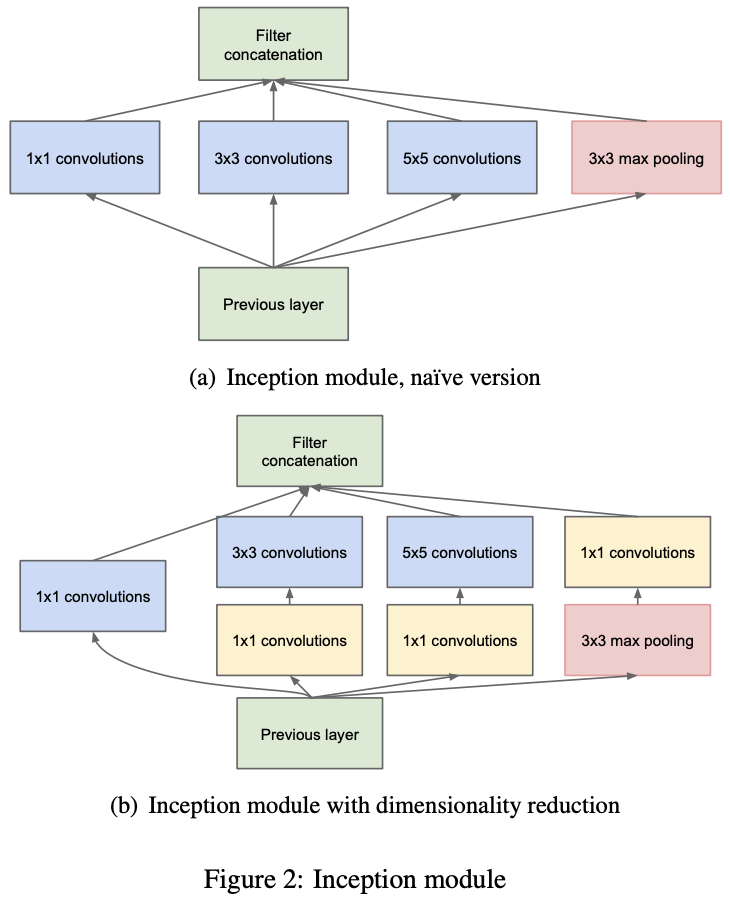
受到 Network In Network以及 HeHebbian Principle 的启发,作者通过增加网络的宽度,从而提高网络的表达能力,并尝试找到卷积神经网络中的最优局部稀疏结构,即 Inception Module(如上图所示)。
作者所设计的 Inception Module 与常见的网络结构不同,打破了常规的卷积层串联的设计思路,选择将卷积核大小为 1 × 1,3 × 3,5 × 5 的卷积层和池化核大小为 3 × 3 的池化层进行并联,并将各自所得到的特征图进行 Concatenate 操作合并在一起,作为后续的输入。
之所以 Inception Module 由上图左侧发展被改进为上图右侧,是因为:作者希望希望模型中深层的 Inception Module 可以捕捉到 Higher Abstraction,所以作者认为深层的 Inception Module中的卷积层的空间集中度应该逐渐降低,以此捕捉更大面积的特征。故,作者令越深层的 Inception Module 中,卷积核大小为 3 × 3 和 5 × 5 这两个卷积层的输出通道数占比越多。但这又将导致计算量增加,所以为了解决这个问题,作者在原有 Inception Module 的基础上,利用卷积核大小为 1 × 1 的卷积层进行降维操作,从而减小计算量(这建立在一个假设之上:即使是低维的映射也可能包含关于相关图像区域的大量信息)。
由于 Inception Module 保持了输入输出的尺寸一致,故 GoogLeNet 可以由 Inception Module 进行模块化搭建。仔细观察 GoogLeNet 的结构,你会发现作者在 Inception Module (4a) 和 (4d) 设置了额外的辅助 Loss,用以增加向后传导的梯度,缓解梯度消失问题,同时增加额外的正则化操作。在文章中,作者指出这样操作的目的主要是使得模型中低层的特征也具备很好的区分能力。(文章中,这两个额外的 Loss 会乘上衰减系数 0.3,与最后的 Loss 相加,作为整个模型的 Loss)
Inception Net V2
论文 发表时间:2015 年
2015 年,谷歌提出了 Batch Normalization 操作,将其添加在之前的 GoogLeNet,并修改了一定的结构与实验设置,得到了 Inception Net V2,在 ImageNet 上达到分类任务超过 GoogLeNet。(关于 BN 的详细笔记,可以参考这篇博文: 神经网络中 Normalization 的发展历程)
网络结构:
- 将 Inception Module 中卷积核大小为 5 × 5 的卷积层用两个相连的卷积核大小为 3 × 3 的卷积层进行替换。作者指出,这一操作是的模型参数增加了 25%,计算成本提高了 30%。
- 将输出大小为 28 × 28 的 Inception Module 的个数由两个提升到三个,即增加 Inception Module (3c)。
- 在 Inception Module 中进行池化操作(有时为平均池化(Average Pooling),有时为最大池化(Max Pooling))
- 两个 Inception Module 之间不再进行池化操作,仅在 Inception Module (3c) 和 (4e) 前添加 stride-2 conv/pooling layer。
- 将网络第一层的卷积层替换为深度乘子为 8 的可分离卷积(Separable Convolution,关于这个概念,可以参考:卷积神经网络中的Separable Convolution 和 CNN中千奇百怪的卷积方式大汇总)。
其他细节:
作者在文中指出,他们并不是直接简单的将 BN 添加到网络中的,还做了如下的改动:增大学习率,移除 Dropout,减小 L2 正则化项,加速学习率衰减,移除 LRN,更彻底的打乱训练数据,减少光学畸变( Photometric Distortion,关于这个概念,可以参考这篇文章:SSD中的数据增强细节)。
Inception Net V3
论文 发表时间:2015 年
时隔将近一年,谷歌又发了篇论文对之前提出的 Inception Module 进行了思考。在这篇论文中,作者首先四条设计神经网络的原则,接着提出如何分解大卷积核的卷积层,接着反思辅助分类器(Auxiliary Classifier)的作用,接着按照自己所提的第一条原则对常见的 Size Reduction 做了改进,最后将以上改进添加进之前的网络结构中。
关于四条设计神经网络的原则:
- Avoid representational bottlenecks, especially early in the network.
- Higher dimensional representations are easier to process locally within a network.
- Spatial aggregation can be done over lower dimensional embeddings without much or any loss in representational power.
- Balance the width and depth of the network.
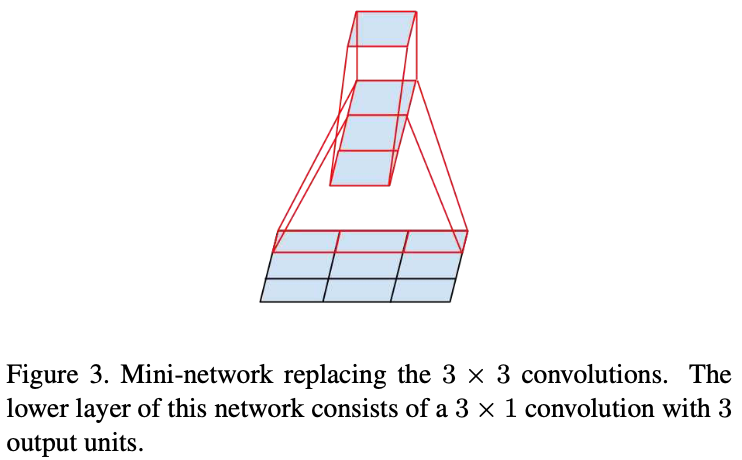
关于如何分解大卷积核的卷积层:
作者提出两种解决办法:利用连续的两层小卷积核的卷积层代替大卷积核的卷积层(下图左侧所示);利用连续的两层非对称的卷积层(卷积核大小为 n × 1 和 1 × n)代替原有卷积层(卷积核大小为 n × n)(下图右侧所示)。
这样做的好处自然是减少参数量以及计算量。此外,作者对于这两种操作都做了相应的实验并发现:使用第一种操作时,添加在卷积层后的激活函数都为 ReLU 比 Linear+ReLU 好;使用第二种操作,最好在模型的中间层使用(适用的FeatureMap大小范围为 12~20)。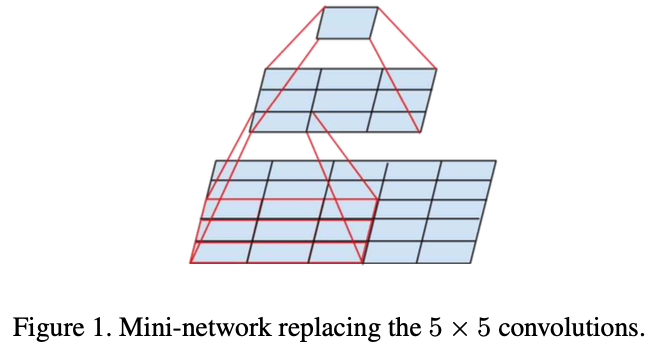
关于辅助分类器的作用:
GoogLeNet 曾在 Inception Module (4a) 和 (4d) 设置了额外的辅助 Loss,即设置了辅助分类器,当时作者对其的理解是:使梯度更好的回传到低层,避免梯度消失问题,提高模型的收敛速度与最终表现。但是作者通过实验发现:在训练初期,有无辅助分类器并无区别;在训练后期,有辅助分类器将提高模型的最终表现;此外,作者去掉 GoogLeNet 中较低的辅助分类器的分支,发现此举并不会导致模型性能有明显的降低。最后,作者认为:辅助分类器起到的作用更像是正则化。
关于如何有效减少特征图尺寸:
在分类任务中,许多模型都会随着深度的整长不断通过池化操作缩小特征图尺寸,以此减小模型的“体积”。由于池化操作会导致特征图中的许多信息丢失,许多模型都习惯在特征图的宽与高缩小一半的同时,利用卷积核为 1 × 1 的卷积层使得特征图的通道数量翻倍(即 C × W × H -> 2C × W/2 × H/2),以此减少池化操作所带来的信息丢失。
这样操作有两种选择:先进行升维操作,再进行池化操作;先进行池化操作,再进行升维操作。作者指出,根据原则一,我们应先进行升维操作,再进行池化操作。(我觉得挺好理解的,本来升维就是为了避免池化操作带来的信息丢失,但是在已经池化后的特征图上做升维的效果肯定不如在未池化的特征图上做升维的效果好)
当然,这样做会导致计算量增加,于是作者提出了另一种做法,如下图所示: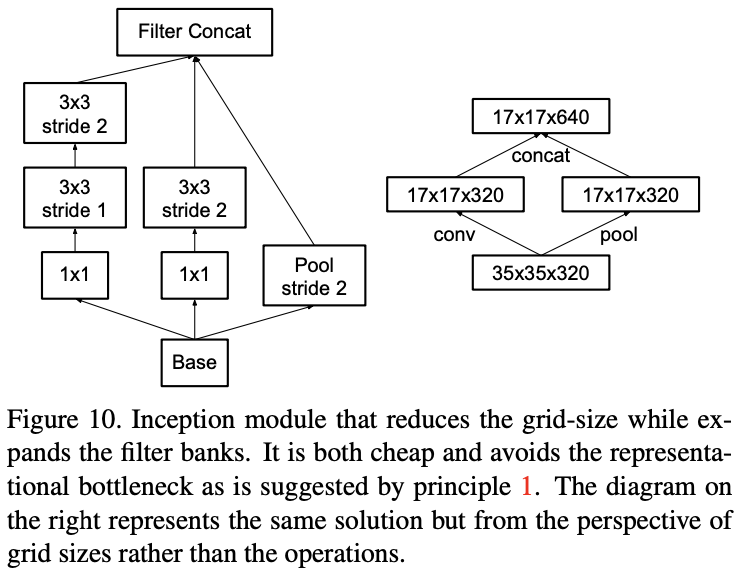
Inception Net V4
论文 发表时间:2016 年
在 Inception-v4 中,作者将 Inception 和 ResNet 结合在一起,推出了 Inception-ResNet-v1,Inception-ResNet-v2,Inception-v4。其中,Inception-v4 的总体结构如上图所示,各个模块细节如下图所示。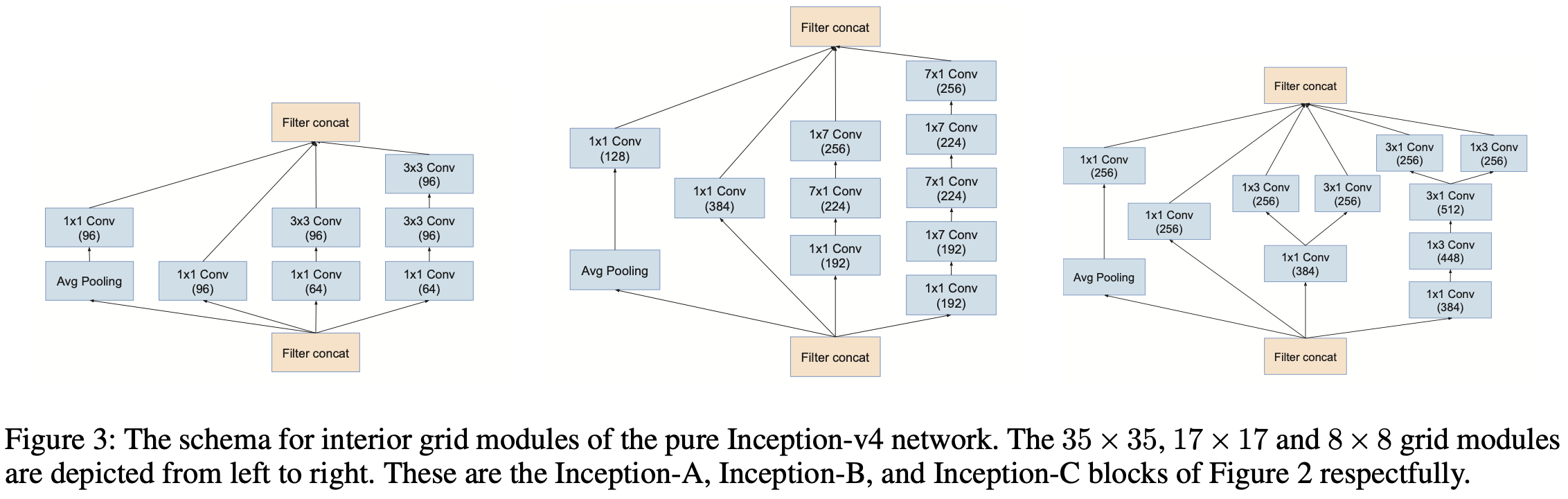
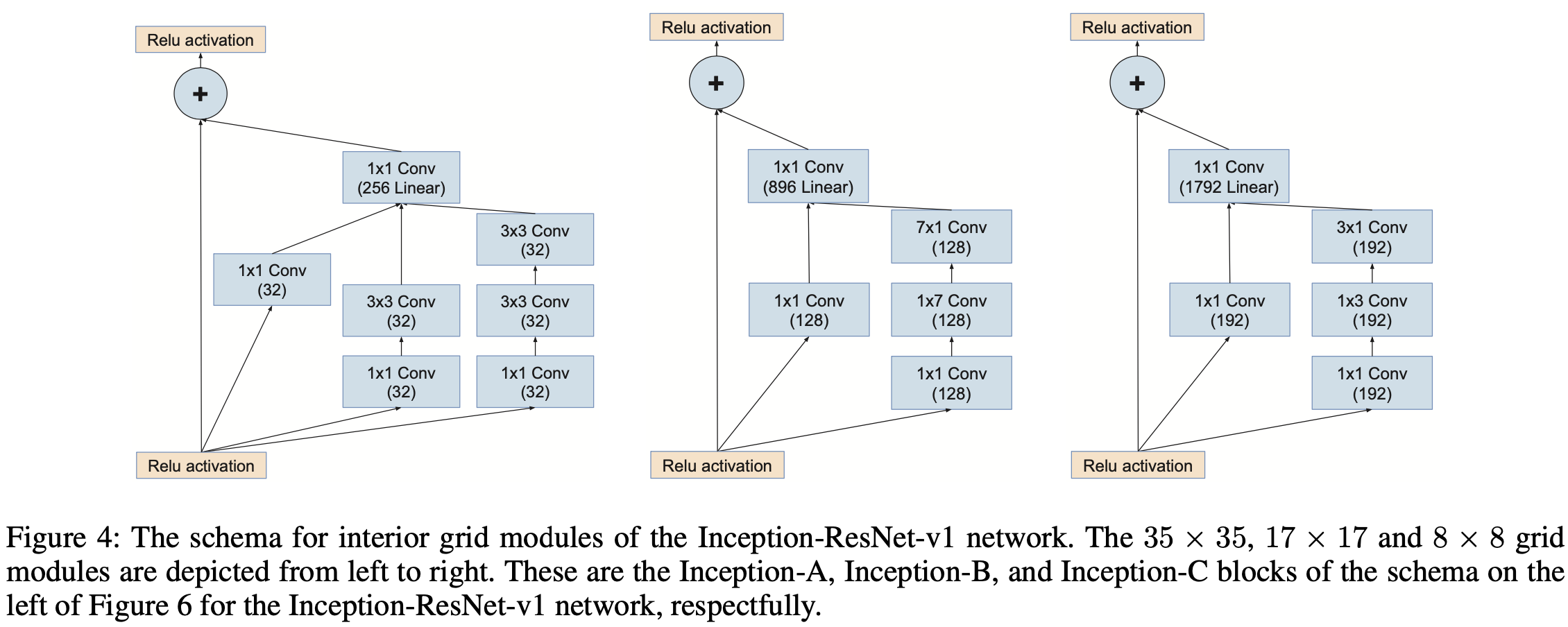
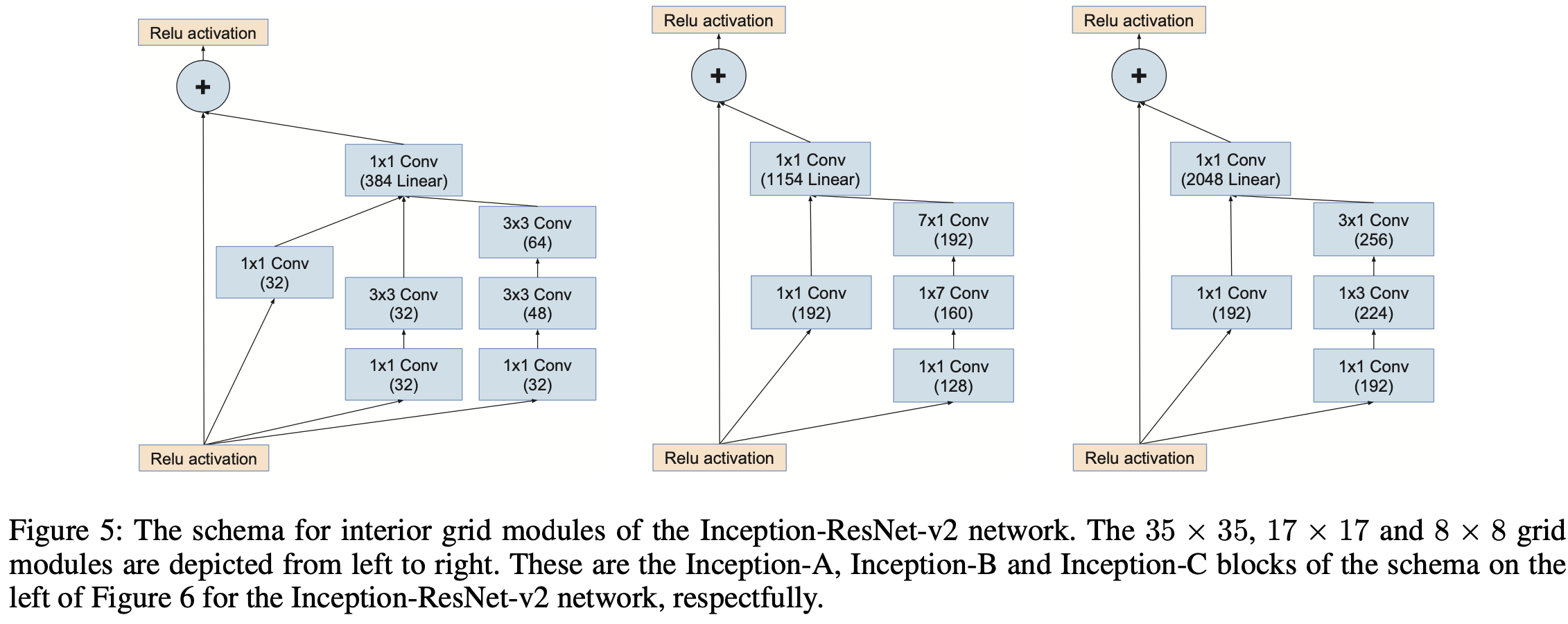
可以看得出来,Inception-v4 的结构设计非常复杂,需要大量的实验验证以及工程经验,一般只有大厂才有能力做这样的工作,这也是为什么最近 NAS 这么火的原因吧。
Xception
论文 发表时间:2016 年
在这篇论文中,Google 利用 Depthwise Separable Convolution 对 Inception V3 进行了改进,并结合 Residual Connection 设计了新的网络:Xception(含有 Extreme Inception 的意味)。
作者在文章开头便指出 Inception Module 背后的思路是通过一系列操作使得模型的学习更加简单有效(分别单独学习通道之间的关系和空间关系),这意味着 Inception Module 假设通道之间的关系和空间关系是可以被分离开的(这个假设的一个变体就是 width-wise correlation and height-wise correlation,即 Inception V3 里的卷积核大小为 7×1 和 1×7 的卷积层)。接着,作者由 Inception V3 中的 Inception Module 进行演变,得到极端版本的 Inception Module,与 Depthwise Separable Convulotion 思路一致,如下图所示: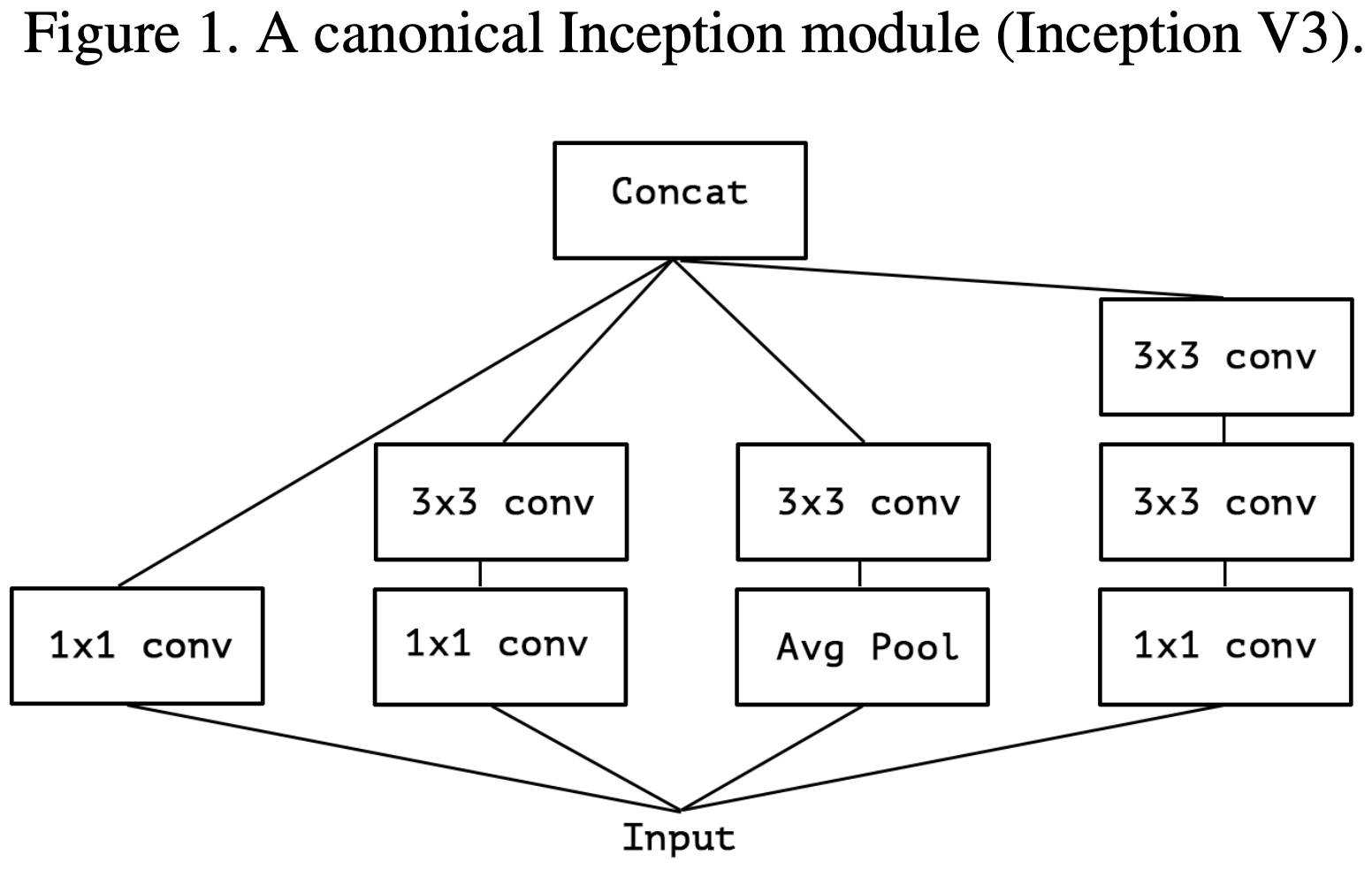
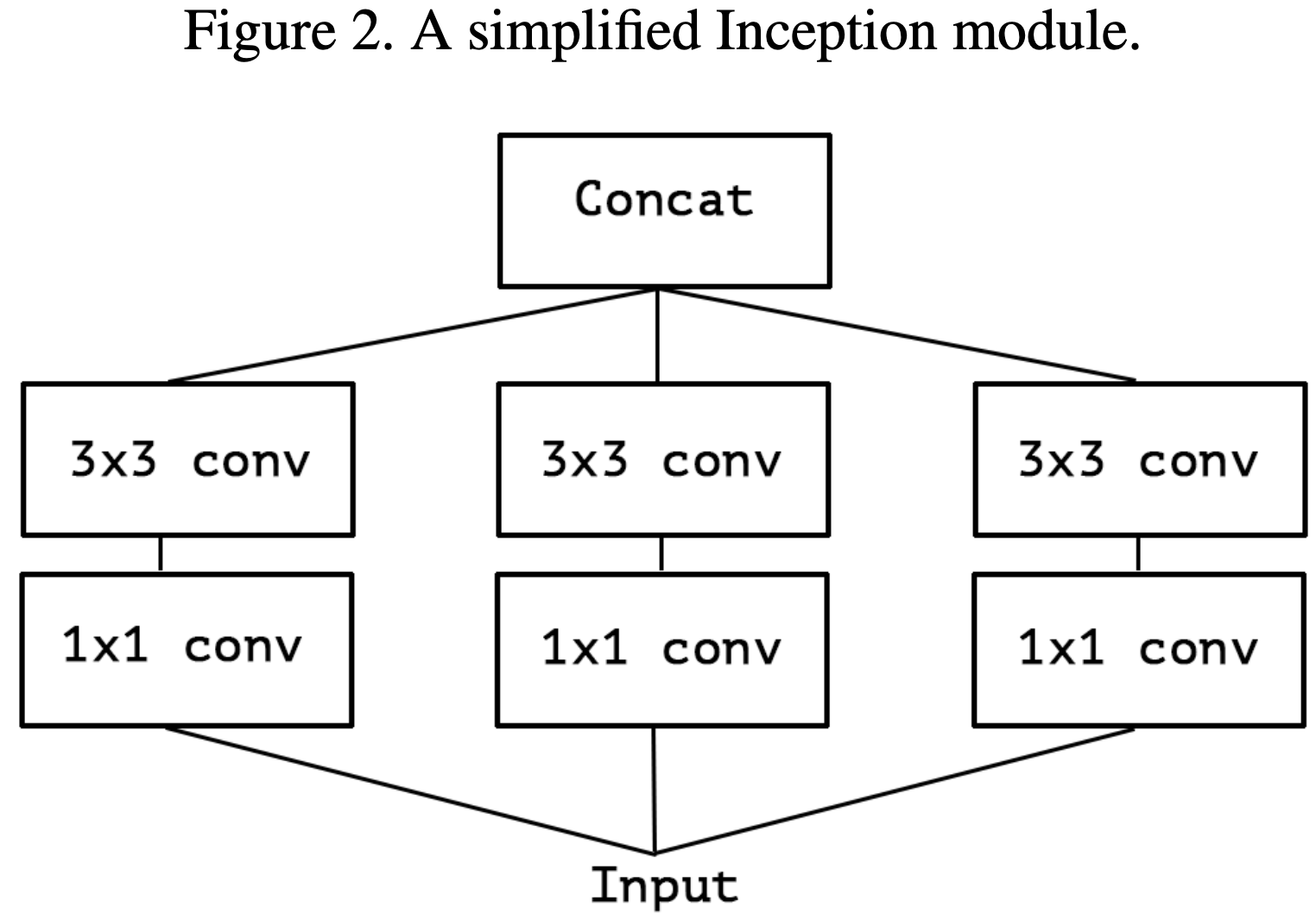
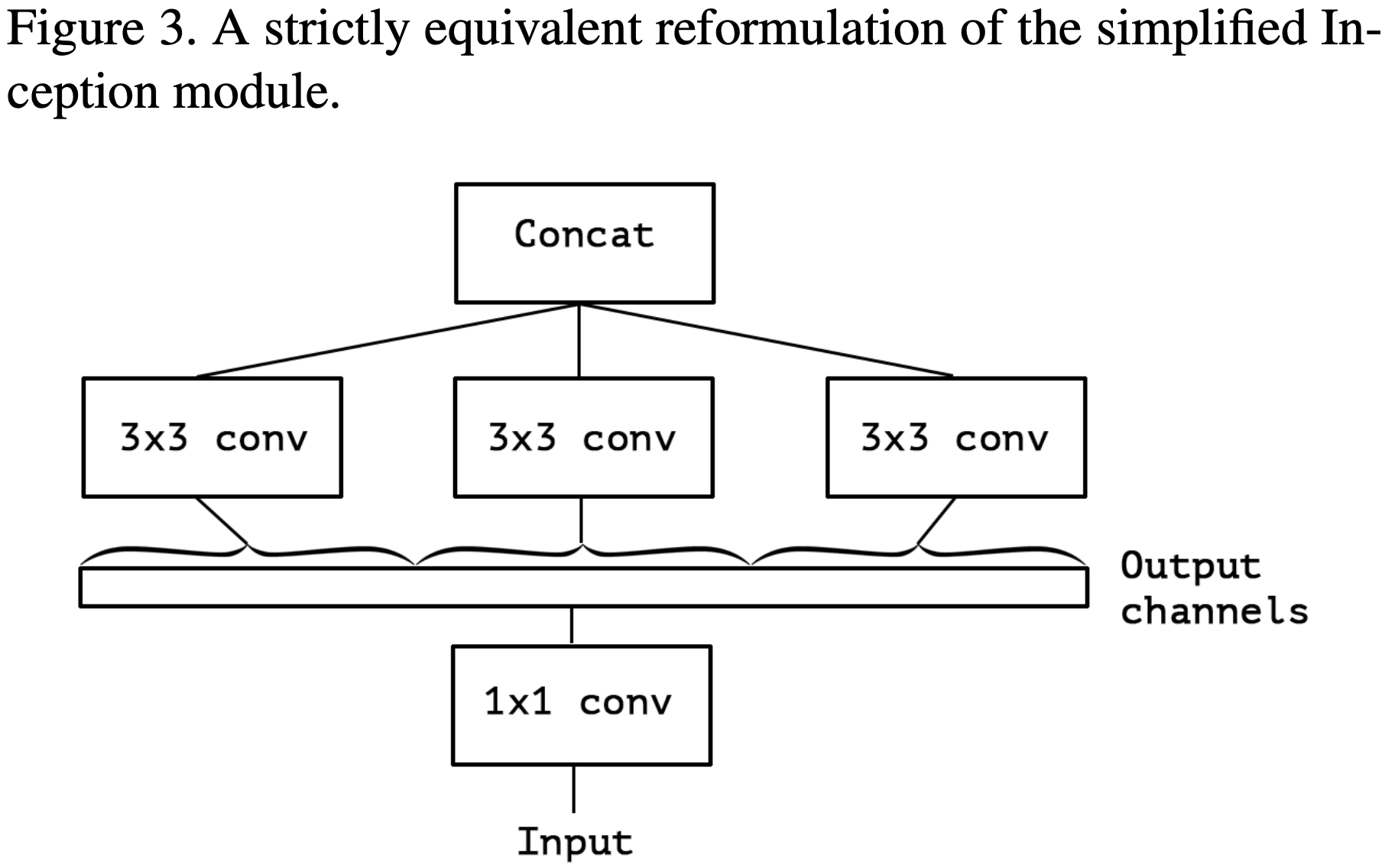
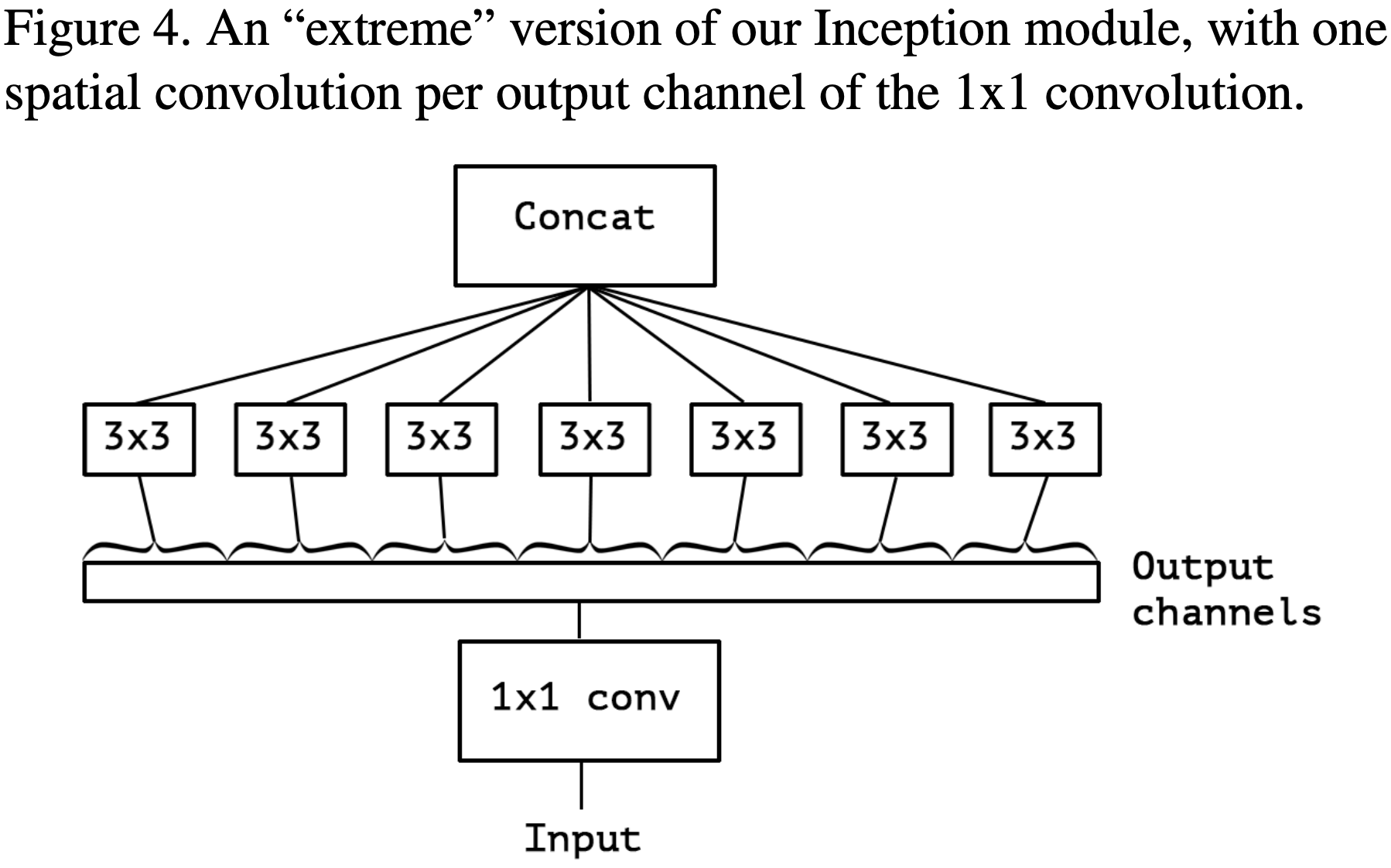
作者指出 “extreme” version of Inception Module 与 Depthwise Separable Convolution 主要存在两点不同:
- Depthwise Convolution 和 Pointwise Convolution 的顺序不同。不过,作者认为这一点并不重要。
- 在 Inception Module 中,Depthwise Convolution 和 Pointwise Convolution 后都会接着 ReLU;而 Depthwise Separable Convolution 一般仅在 Pointwise Convolution 后接着 ReLU。作者认为这一点差异比较重要,并在后续的实验中进行了讨论(后面发现在 Pointwise Convolution 后接 ReLU/ELU,都不如中间不添加激活函数的表现效果)。
最后,作者提出了新的网络:Xception(结合了 Inception Module, Residual Connection, Depthwise Seperable Convolution),网络结构如下所示: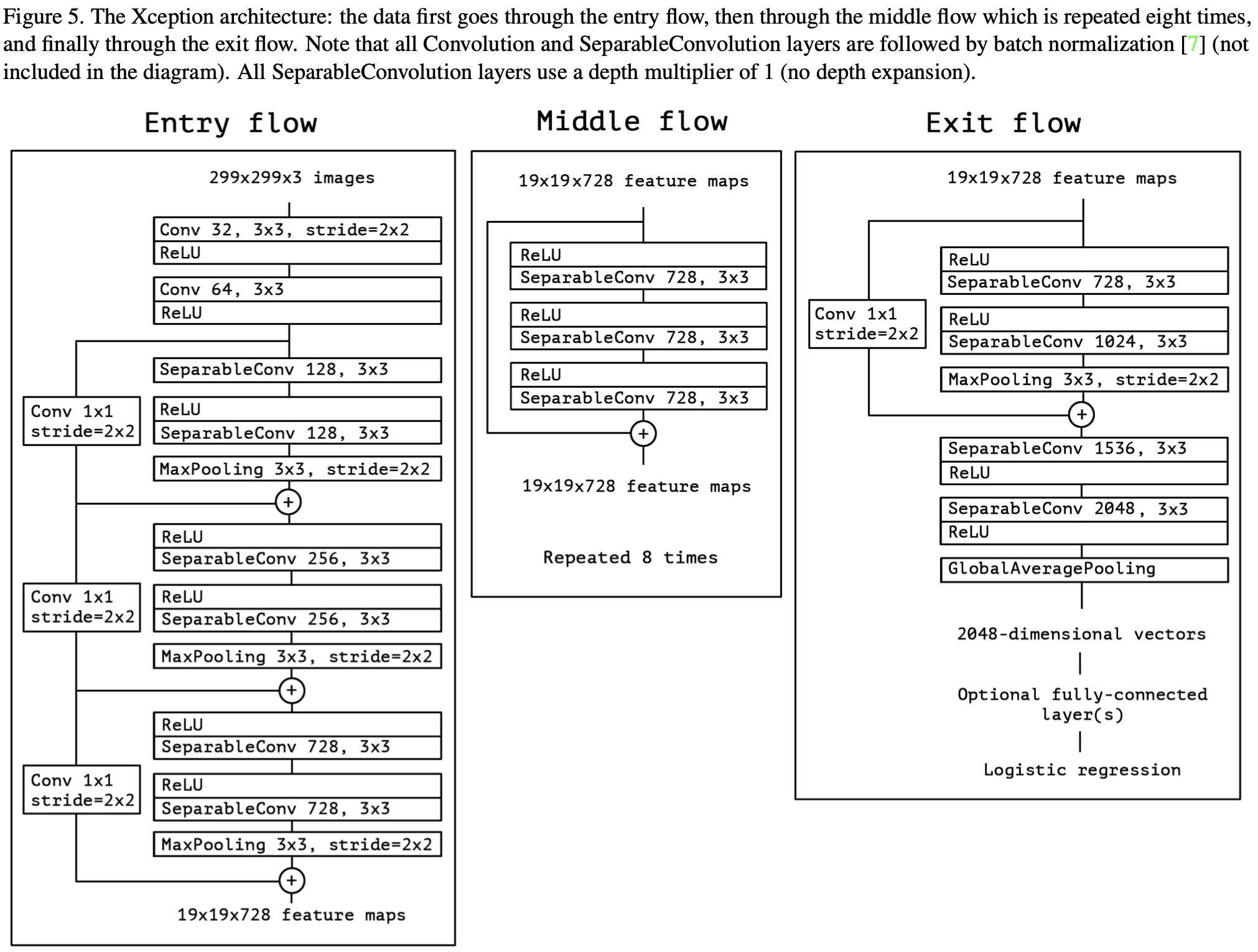
ResNet
论文 发表时间:2015 年
2015 年,Kaiming He 提出了 ResNet(拿到了 2016 年 CVPR Best Paper Award),不仅解决了神经网络中的退化问题(Degrade Problem,即相较于浅层神经网络,深层神经网络的深度到达一定深度后,拟合能力反而更差,训练/测试误差更高),还在同年的 ILSVRC 和 COCO 竞赛横扫竞争对手,分别拿下分类、定位、检测、分割任务的第一名。(个人觉得,ResNet真的属于现象级论文,所提出的残差结构大幅提高了神经网络的拟合能力)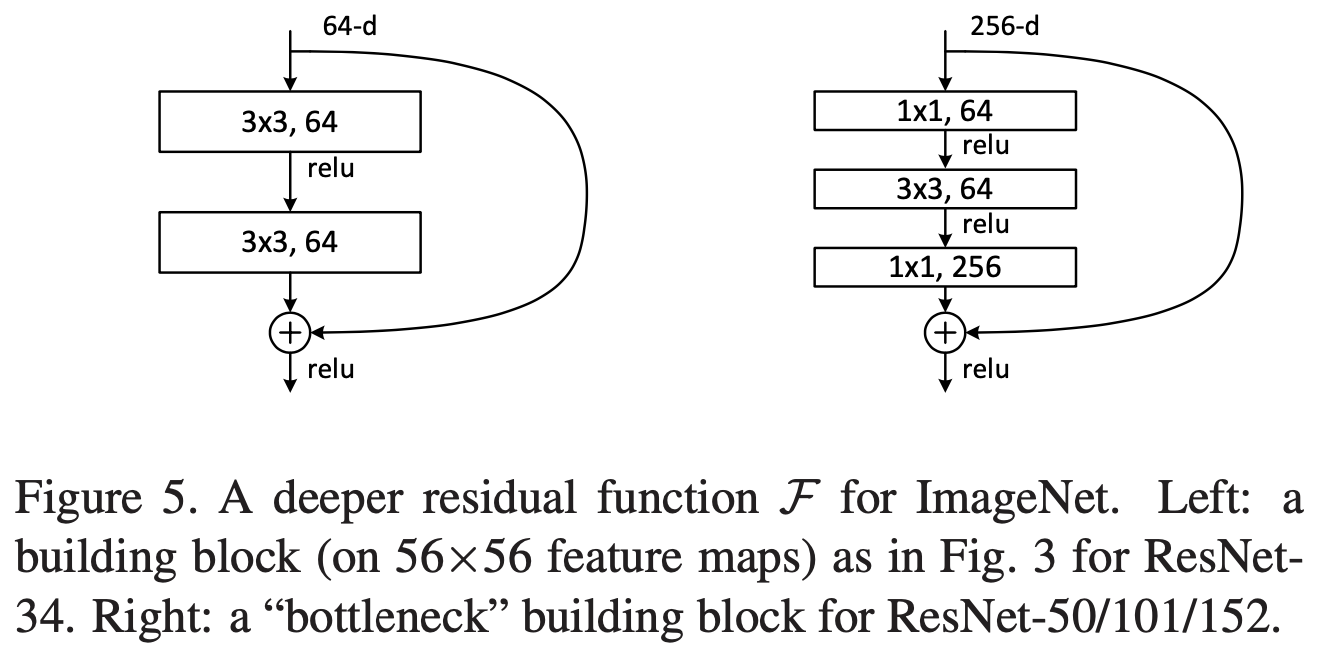
网络结构:
简单来说,Kaiming 在文中提出了残差结构(Residual Block,如上图左侧所示),使得原本所要拟合的函数$H(x)$ ,改为$F(x)$ ,其中,$H(x)=F(x)+x$ 。虽然在“多个非线性层可以拟合任意函数”这一假设下二者并无区别,但是 Kaiming 假设模型学习后者,将更容易进行优化与收敛。(在残差结构中,模型利用 Shortcut 进行 Identity Mapping,这样也解决了梯度消失现象)
由于 Residual Block 并不需要额外的参数以及计算量,Kaiming 在文中以此做了多组对照实验,证明该网络结构的有效性(所用的两个 ResNet 为 ResNet-18 和 ResNet-34)。但是,若要将模型的深度继续不断增加,需要对其进行改进:将原先的 Residual Block(上图右侧所示,也被称作 Basic Block) 改进为 Bottleneck Block,减少模型的参数与计算量。
其他细节: - 对训练数据进行数据增强:从 [256,480] 随机采样,作为图像最短边长度,进行宽高等比缩放;随机裁剪 224 * 224,并进行随机镜像翻转;并对所有训练图像的每个像素值进行统计,并减去该平均值。
- 对测试数据使用 10-crop 测试方法。
- ResNet 在非线性层后,激活函数前使用 Batch Normalization。
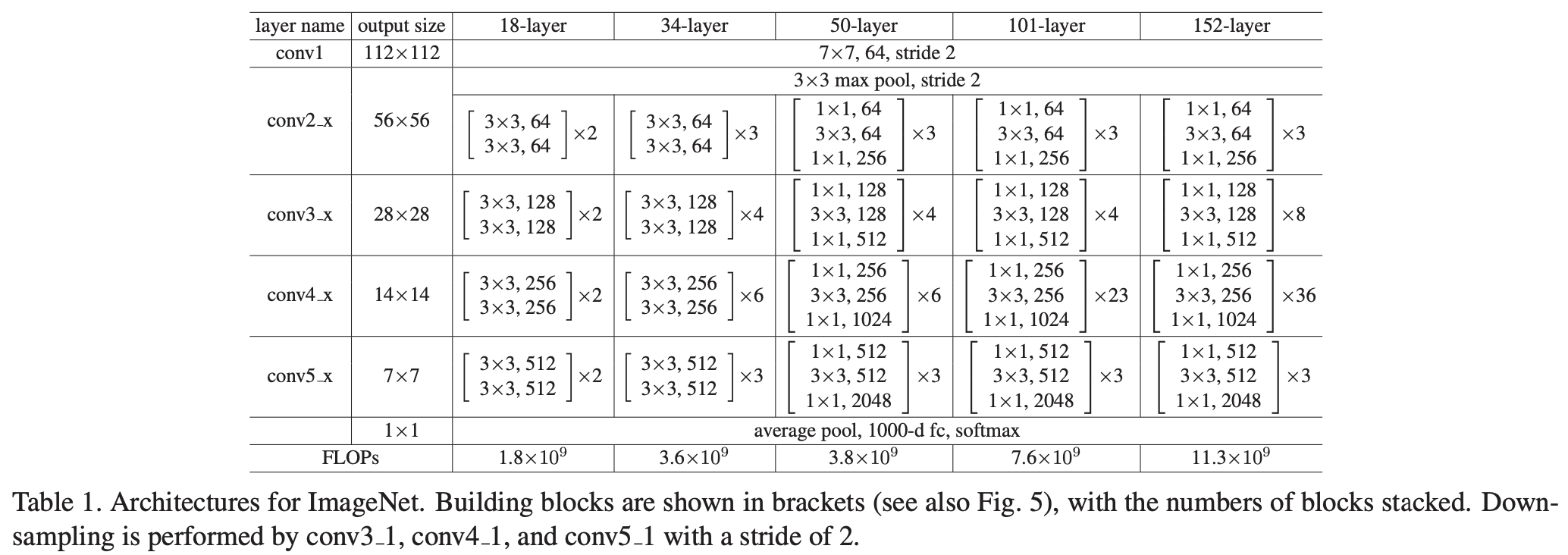
PyTorch 中的 TORCHVISION.MODELS 提供基于 ImageNet 训练好的 ResNet-18/ResNet-34/ResNet-50/ResNet-101/ResNet-152 模型,以及对应使用 Batch Normalization 的版本,分别将其加载到显存中占了 1007/1113/1179/1227/1443 MiB(训练与测试所占显存大小依赖于实验设置,故不做讨论)。
关于 Residual Network 中 Identity Mapping 的讨论
论文 发表时间:2015 年
Kaiming 在这篇论文中对 ResNet 中的 Identity Mapping 进行了详细的讨论(前向传导、后向传导的分析),并且设计并尝试了多种不同的 Shortcut Connection 设计(如上图所示),并在最后对激活函数做了讨论,从而提出了新的 Residual Block(为与原版结构区分,Kaiming 称其为 full pre-activateion Residual Block)。
我个人是比较喜欢这篇论文的,不仅对照实验设置的很详细,也对各类实验现象进行了分析,尤其是最后关于激活函数的讨论(到现在为止,这应该都还是开放问题,大家并没有一个统一的观点)。总的来说,Kaiming 在这篇论文中做出了两处改动:移除了 Short Connection 中的 ReLU,并将 Residual Mapping 中的 BN 和 ReLU 提前至对应的神经网络层前。
阅读 PyTorch 所提供的源码,可以发现 PyTorch 中的 TORCHVISION.MODELS 所提供的 ResNet 模型,都是按照之前文章所述实现的,即 original Residual Block 版本。
DenseNet
论文 发表时间:2016 年
2016 年,DenseNet 横空出世,在当年也引起过热议。与 ResNet、Inception Net 不同,DenseNet 即没从网络的深度入手,也没从网络的宽度入手,而是对每层的 FeatureMap 进行特征复用,以此缓解梯度消失问题,加强网络中特征的传递,有效对特征进行复用,并在提高网络的表现效果的同时减少了网络的参数量!
在论文中,作者提出了一种网络结构:Dense Block(如下图所示)。在 Dense Block 中,每层卷积层的输入为在该 Block 中之前所有卷积层所输出的 FeatureMap 的 concation 结果 (此处与 ResNet 不同,ResNet 中将结果进行 add )。作者在文中指出,ResNet 成功的关键点在于:‘they create short paths from early layers to later laters’;作者认为自己之所以提出的 Dense Block 这样的结果,就是为了保证层与层之间的信息能最大程度的保存。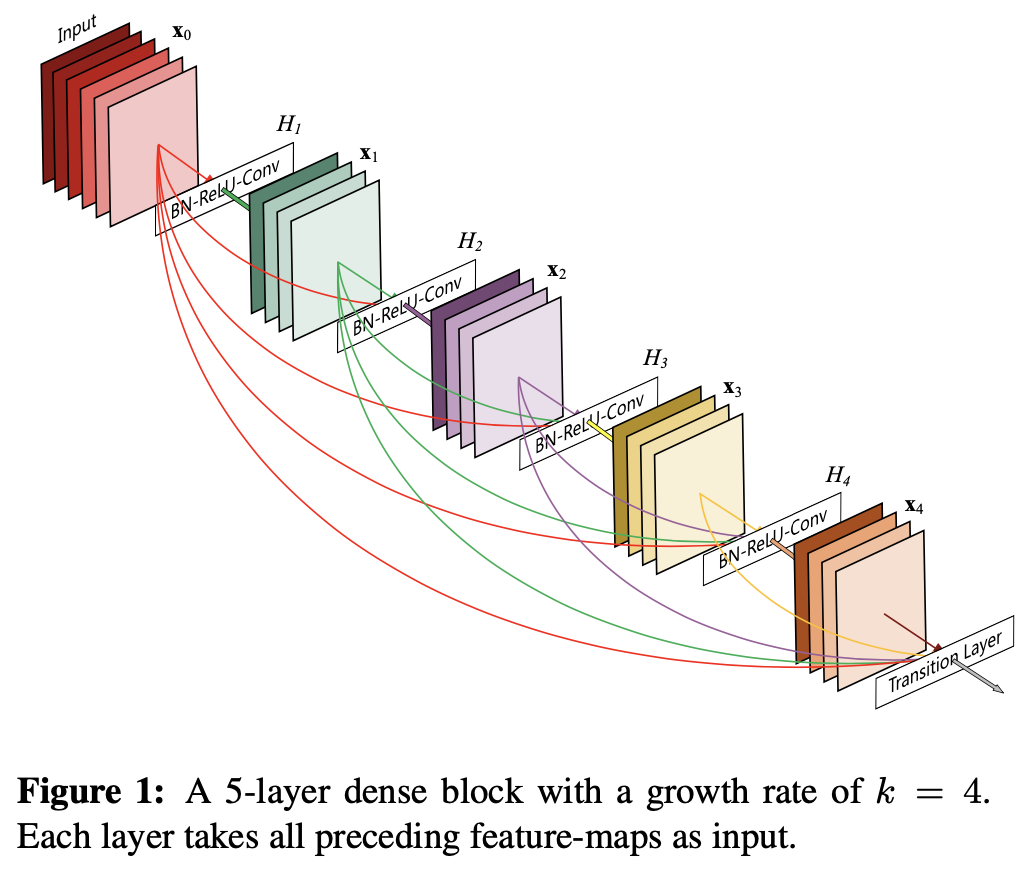
网络结构:
- DenseNet 与其他 CNN 类似,同样保留着 down-sampling layers 的设计,网络中包含四个 Dense Block 和四个 Transition Layer,分别处理不同 Size 的 FeatureMap / 对 FeatureMap 进行 Pooling 操作。
- 根据 Identity Mappings in Deep Residual Networks,作者在 Dense Block 中将 BN 和 ReLU 设置在卷积层前面。由于 Dense Block 的特征复用操作,越后面的卷积层,其输入的 Channel 越大。故作者在 DenseNet 中引用了 Bottleneck Layer,即:BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3),以此避免计算量的快速增长。(文中记使用 Bottleneck Layer 的 DesnseNet 为 DenseNet-B)
- 作者还尝试在 Transition Layer 中对 FeatureMap 的 Channel 数量进行缩减,设输入的 FeatureMap 的 Channel 数为 m, $\theta$ 为压缩因子,则输出的 FeatureMap 的 Channel 数为 $\theta_m$ 。(实验中,作者设置 $\theta$ 为0.5;,并记使用 Bottleneck Layer 以及设置 Transition Layer 的 $\theta$ 的 DesnseNet 为 DenseNet-BC)
- 为保持特征复用的实现(即同意 DenseNet 中的所有 FeatureMap 大小一致),作者令 Dense Block 中的卷积层的卷积核大小为 3 × 3,padding 为 1,且采用 zero-padding。

PyTorch 中的 TORCHVISION.MODELS 提供基于 ImageNet 训练好的 DenseNet-121/DenseNet-161/DenseNet-169/DenseNet-201 模型,分别将其加载到显存中占了 1115/1201/1135/1153 MiB(训练与测试所占显存大小依赖于实验设置,故不做讨论)。
MobileNet
论文 发表时间:2017 年
(关于 MobileNet 系列文章,可以参考\博文:MobileNet 系列论文笔记)
2017年左右,神经网络模型轻量化已经逐渐引起人们的关注,常见的手段分为两种:设计轻量化网络模型以及对已经训练好的复杂网络进行压缩(比如:降低精度、剪枝等等)。此时,Google 提出了一个轻量化模型:MobileNet,成为后续人们常使用的 Baseline Model。
在 MobileNet 中,作者利用 Depthwise Separable Convolution 设计了一个轻量化网络,并通过设置 Width Multiplier 和 Resolution Multiplier 这两个超参数方便用户根据需求任意更改网络宽度与输入分辨率大小,从而使得人们可以根据任务需要与实际场景对模型进行 latency 和 accuracy 的权衡。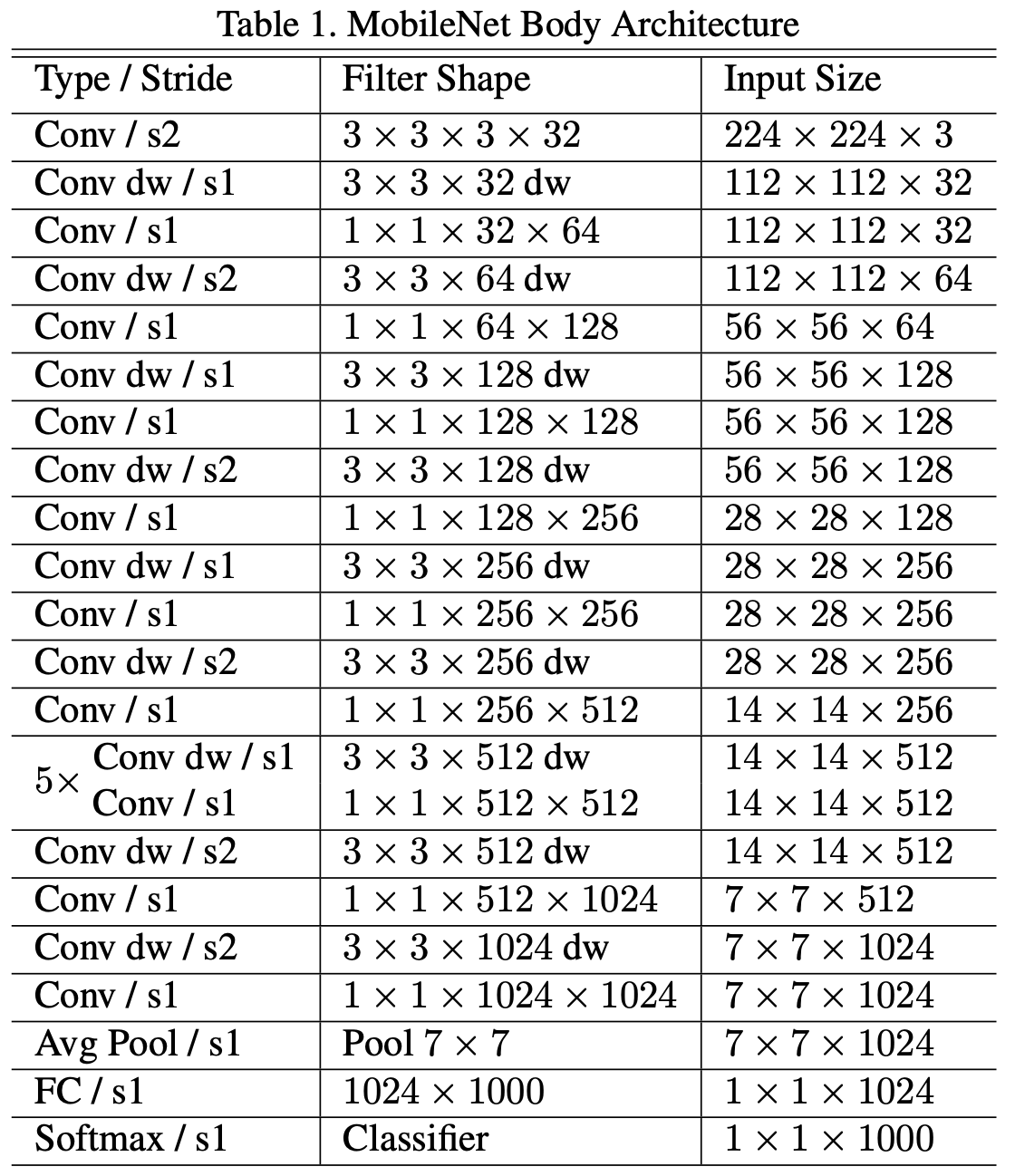
关于 Depthwise Separable Convolution:
Depthwise Separable Convolution 其实是将 Standard Convolution 拆分成两个部分:Depthwise Convolution 和 Pointwise Convolution。
其实这个概念不难理解,只需要看作者所提供的图就好了:
原先的 Standard Convolution 中每个 Filter 的 shape 为$(D_k,D_k,M)$,其中 $M$ 为所输入 Feature Map 的 Channel 数。每个 Filter 在所输入的 Feature Map 上进行卷积,输出的 Shape 为 $(D_out,D_out,1)$ ,如果有 $N$ 个 Fliter,则输出的 Shape 为 $(D_out,D_out,N)$。
反观 Depthwise Separasble Convolution:在 Depthwise Convolution 阶段,每个 Depthwise Convolution Fliter 的 Shape 为 $(D_k,D_k,1)$ ,共有 $M$ 个 Filer,则输出结果的 Shape 为 $(D_out,D_out,M)$ ;接着在 Pointwise Convolution 阶段, 每个 Pointwise Convolution Filter 的 Shape 为 $(1,1,M)$ ,共有 $N$ 个 Filter,则输出结果的 Shape 为 $(D_out,D_out,N)$。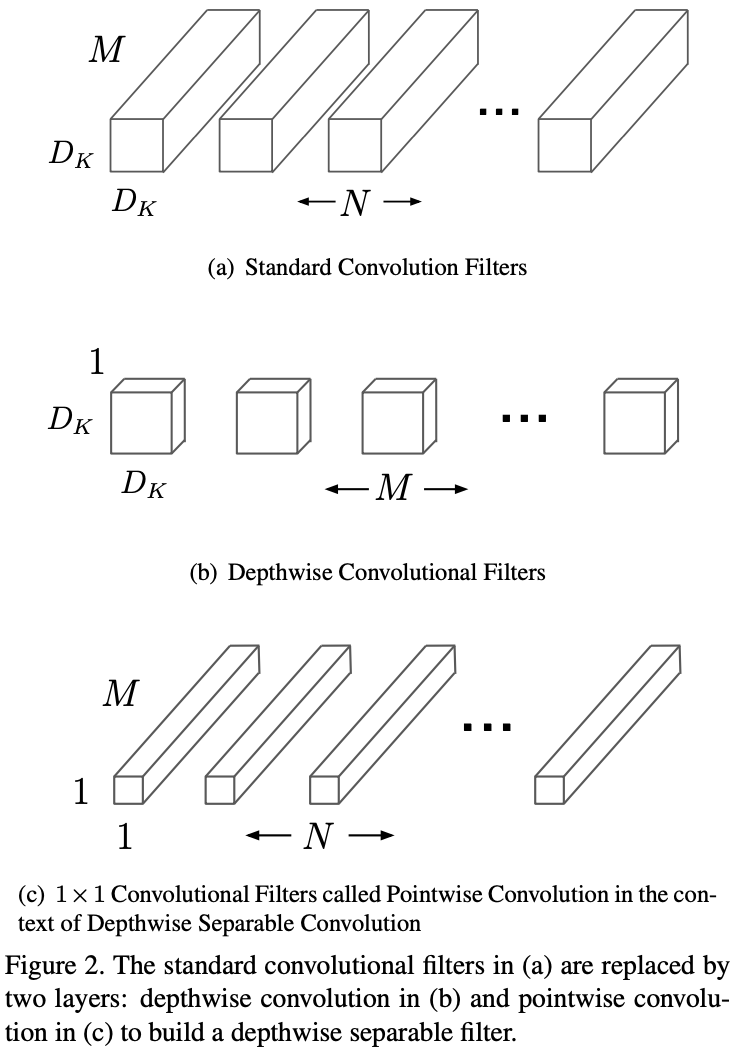
可以明显看出,Standard Convolution 所需参数为 $D_k D_k M N$ ,而 Depthwise Separable Convolution 所需参数为$D_k D_k M + M N = M (D_k D_k + N)$,与 Standard Convolution 相比,所减少的参数数量为 $(N-1)D_kD_k-N$。
作者在论文中,也分别对 Standard Convolution 和 Depthwise Separable Convolution 的计算代价做了对比: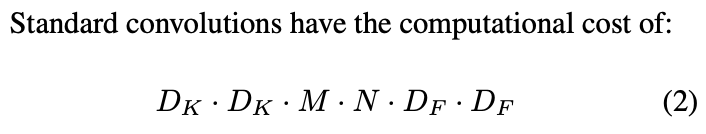
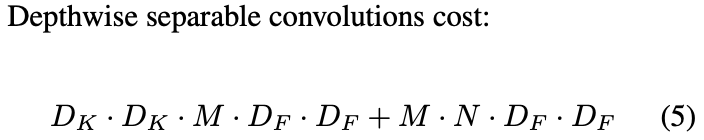
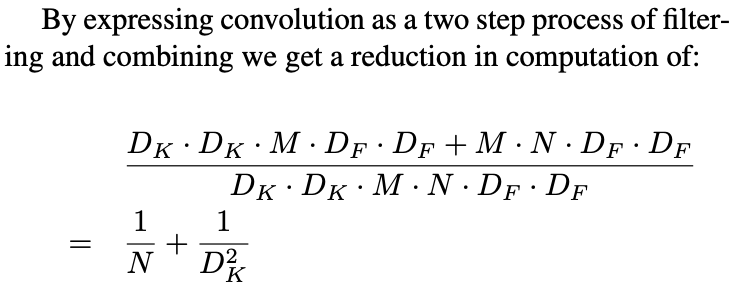
关于 Width Multiplier:
作者在论文中提出,可以利用超参数$\alpha$控制 MobileNet 的通道数,使得输入 Feature Map 的 channel 数变为$\alphaM$,输出 Feature Map 的 Channel 数变为$\alphaN$。
其中,$\alpha = 1$为 baseline MobileNet, $\alpha \lt 1$为 reduced MobileNet。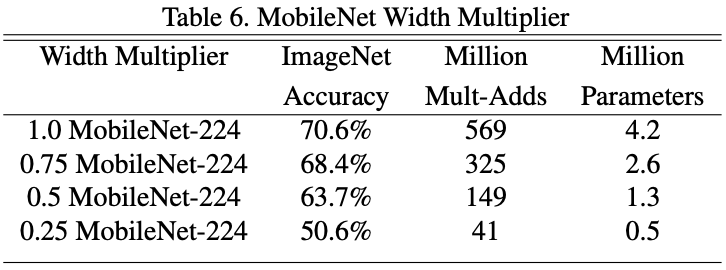
关于 Resolution Multiplier:
作者在论文中提出,可以利用超参数$\beta$控制 MobileNet 的 resolution。
其中,$\beta = 1$为 baseline MobileNet,$\beta \lt 1$为 reduced MobileNet。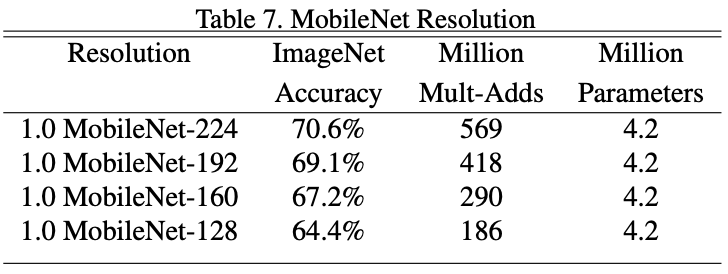
MobileNet V2
论文 发表时间:2018 年
2018年,Google 在 MobileNet 基础上提出了新的模型 MobileNet V2。其中,提出了新的结构 Inverted Residuals and Linear Bottlenecks,并利用MobileNet V2 实现分类/目标检测/语义分割多目标任务。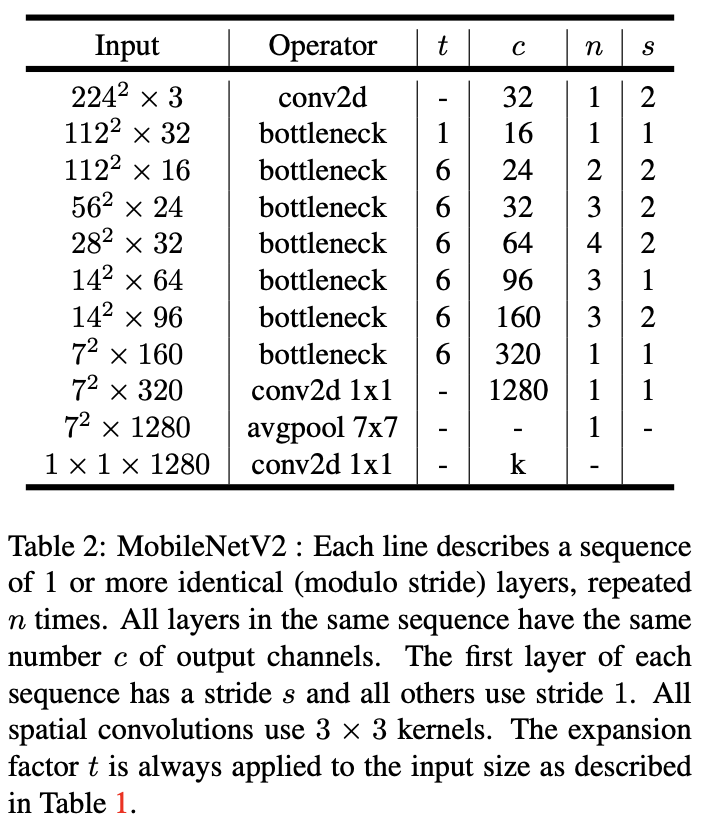
关于 Inverted Residuals and Linear Bottlenecks:
首先,先讲清楚什么是 Inverted Residuals and Linear Bottlenecks 结构:
下图是 Residual Block 与 Invereted Residual Block 的区别,可以看到原先的 Residual block 是先降 Channel 再升 Channel 的,不过现在 Inverted Residual Block 却是先升 Channel 再降 Channel 的。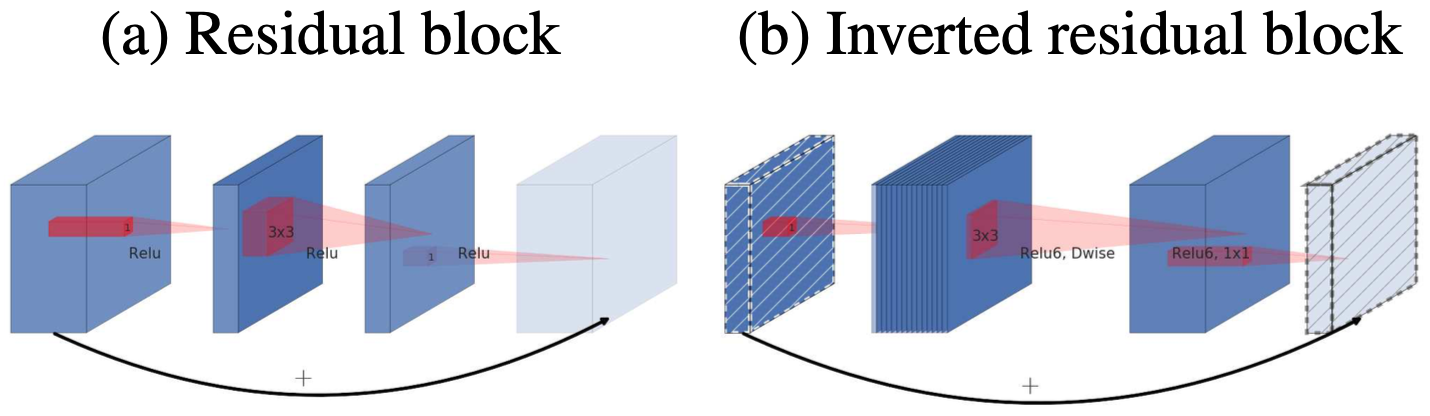
其次是Linear的部分,作者在文中指出 ReLU 的使用将会使得 low-dimension channel tensor 产生崩塌,造成信息损失,故将最后的 ReLU6 去掉,直接进行线性输出。(关于 ReLU6:卷积之后通常会接一个ReLU非线性激活,在Mobile v1里面使用ReLU6,ReLU6就是普通的ReLU但是限制最大输出值为6(对输出值做clip),这是为了在移动端设备float16的低精度的时候,也能有很好的数值分辨率,如果对ReLU的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16无法很好地精确描述如此大范围的数值,带来精度损失。)
作者对于这部分做了详细的实验与推导,在此我尽量进行描述:
作者首先提到 It has been long assumed that manifolds of interest in neural networks could be embedded in low-dimensional subspaces,其次利用实验探究 ReLU 所带来的信息损失:
他人见解:
1.这意味着,在较低维度的张量表示(兴趣流形)上进行ReLU等线性变换会有很大的信息损耗。因而本文提出使用线性变换替代Bottleneck的激活层,而在需要激活的卷积层中,使用较大的M使张量在进行激活前先扩张,整个单元的输入输出是低维张量,而中间的层则用较高维的张量。
2.用线性变换层替换channel数较少的层中的ReLU,这样做的理由是ReLU会对channel数低的张量造成较大的信息损耗。我个人的理解是ReLU会使负值置零,channel数较低时会有相对高的概率使某一维度的张量值全为0,即张量的维度减小了,而且这一过程无法恢复。张量维度的减小即意味着特征描述容量的下降。
关于这部分我的理解比较肤浅,建议大家阅读论文,并查阅他人的见解:
To summarize, we have highlighted two properties that are indicative of the requirement that the manifold of interest should lie in a low-dimensional subspace of the higher-dimensional activation space:
1.If the manifold of interest remains non-zero volume after ReLU transformation, it corresponds to a linear transformation.
2.ReLU is capable of preserving complete information about the input manifold, but only if the input manifold lies in a low-dimensional subspace of the input space.
MobileNet V3
论文 发表时间:2019 年
ShffuleNet V1
论文 发表时间:2017 年
2017年,Face++ 的张翔宇(跟 Kaiming 一起推出 ResNet)推出了 ShffuleNet(一种极高效的移动端卷积神经网络模型),其 Insight 是:许多 Basic Architecture (比如:Xception, ResNet) 在计算资源受限时,其性能将大幅下降,而这是由于其中包含大量的$1*1$ Convolution 所导致的。
因此,在ShffuleNet中,作者利用 Group Convolution, Depthwise Separable Convolution 结合,提出 Pointwise Group Convolution 以避免大量$11$Convoltuion,并利用 Channel Shuffle 缓解由 Group Convolution 带来的副作用,并在 Residual Block 的基础上进行网络结构设计,使得网络的计算量减少的同时,仍能保持较高的性能。
*网络结构:
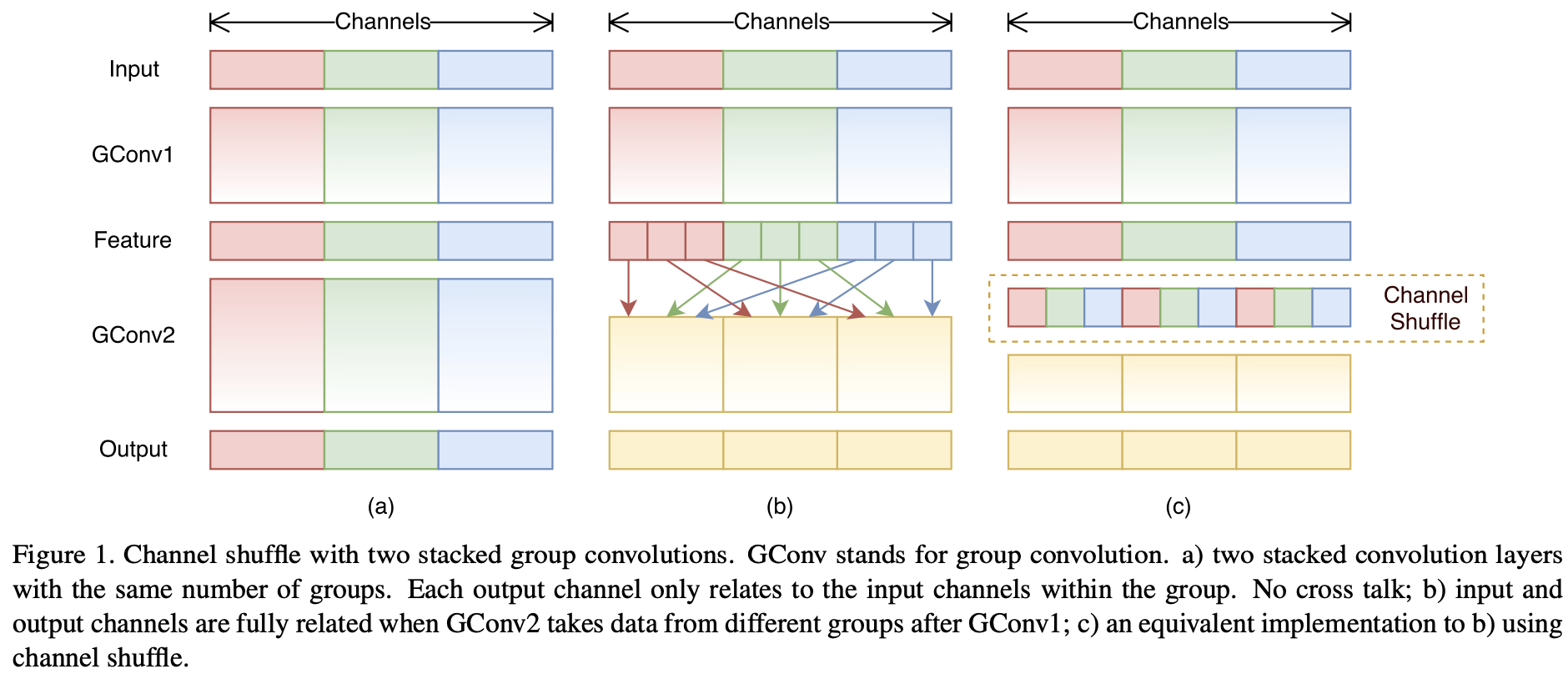
- Group Convolution and Channel Shffule
关于 Group Convolution 的概念,最早应该是在AlexNet中所提出来的,用于解决当时 GPU 显存不够用的尴尬境地。不过,本篇论文中作者利用 Group Convolution 减少模型的计算量与参数量(关于 Group Convolution 的参数量与其他细节可以阅读:Group Convolution分组卷积,以及Depthwise Convolution和Global Depthwise Convolution)。为避免由于 Group Convolution 导致所学习特征较为局限(多个 Group Convolution 叠加,将导致某个输出channel仅仅来自输入channel的一小部分),作者引进 Channel Shuffle 操作作者将 Channel Dimension 由$g*n$reshape 为$(g,n)$,进行转置为(n,g),并进行 flattening,以此完成 Channel Shuffle,使得该操作是可微分的)。
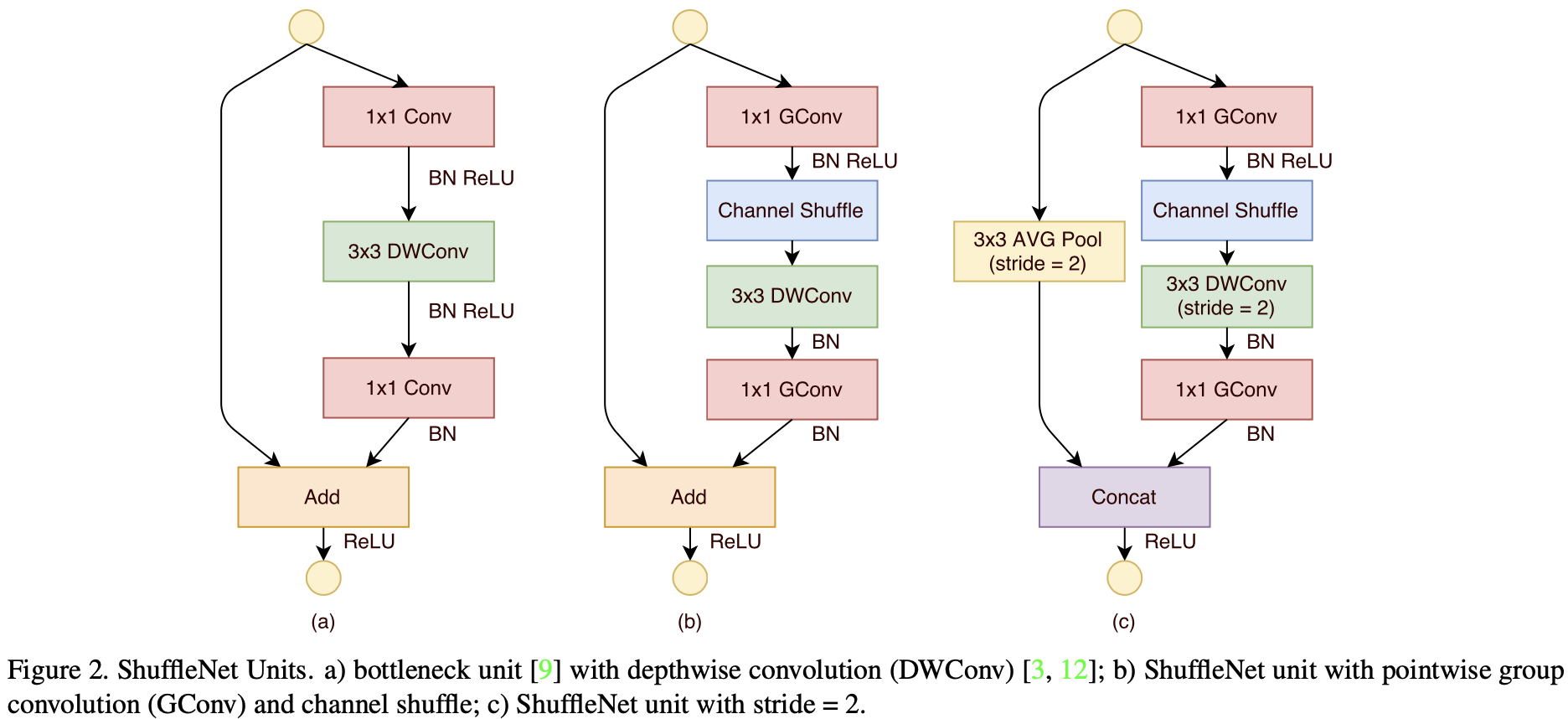
- Depthwise Separable Convolution and Residual Connection
作者利用 Depthwise Separable Convolution 对 Residual Block 进行改进,从而设计出 ShffuleNet Unit。其中,Pointwise Convolution 由于 Group Convolution 的缘故,需改为 Pointwise Group Convolution。作者还指出:之所以不在 Depthwise Convolution 后接 ReLU,是根据 Xception所述;使用 BN 与 ReLU 的方式,是模仿 ResNet 以及 Inception V2。(作者还提到,之所以只利用 Depthwise Convolution 处理 Bottleneck Feature Map,是因为 Depthwise Convolution 很难在移动端上有高效的实现,尽管理论上其参数量与计算量都较小 )
ShuffleNet V2
论文 发表时间:2018 年
近几年来,人们对如何设计高效的神经网络模型的讨论较为热烈,许多针对移动端设备使用的模型结构相继推出,如:MobileNet 系列模型, ShffuleNet 系列模型等等。人们都称这样的网络是“小”网络,衡量标准便是其参数量与运算量,但是这样的衡量标准是否精确呢?
2018年,Face++ 对衡量模型复杂度的指标(如:FLOPs)进行讨论,提出应该使用更为直接的指标(如:运行速度),并应直接在目标平台上进行测试。此外,Face++ 还提出了四条关于高效网络设计的实用准则,并依据此提出了 ShffuleNet V2。
在论文中,作者对 Xception, ShffuleNet V1/V2, MobileNet V2进行了详细测试: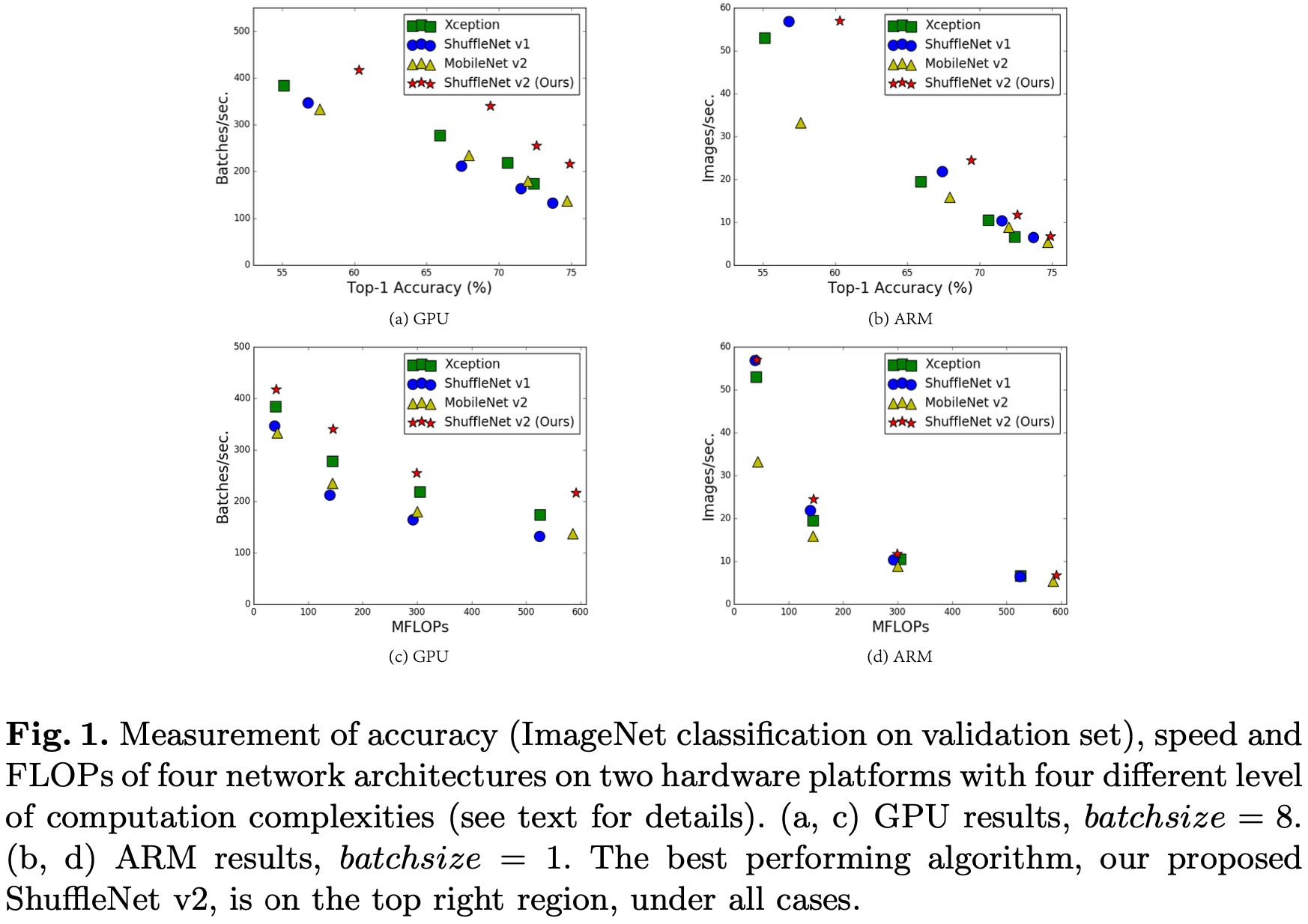
作者认为,之所以出现“运算量差不多的两个模型的速度却会差很多”这一现象,是因为许多影响运行速度的因素并不能通过运算量进行体现,如: Memory Access Cost (MAC) 和模型的并行化程度往往没被纳入考虑范围中,而且模型在不同的平台上的运行速度往往也不一样。
关于高效网络设计的实用准则:
- Equal channel width minimizes memory access cost (MAC).(卷积层输入、输出的通道数量一致可以减少 MAC)
- Excessive group convolution increases MAC.(组卷积的分组数量的增加将导致 MAC 增加)
- Network fragmentation reduces degree of parallelism.(网络过多的分支将影响其并行性能)
- Element-wise operations are non-negligible.(元素级别的操作不应被忽略)
ShffuleNet V2 网络结构: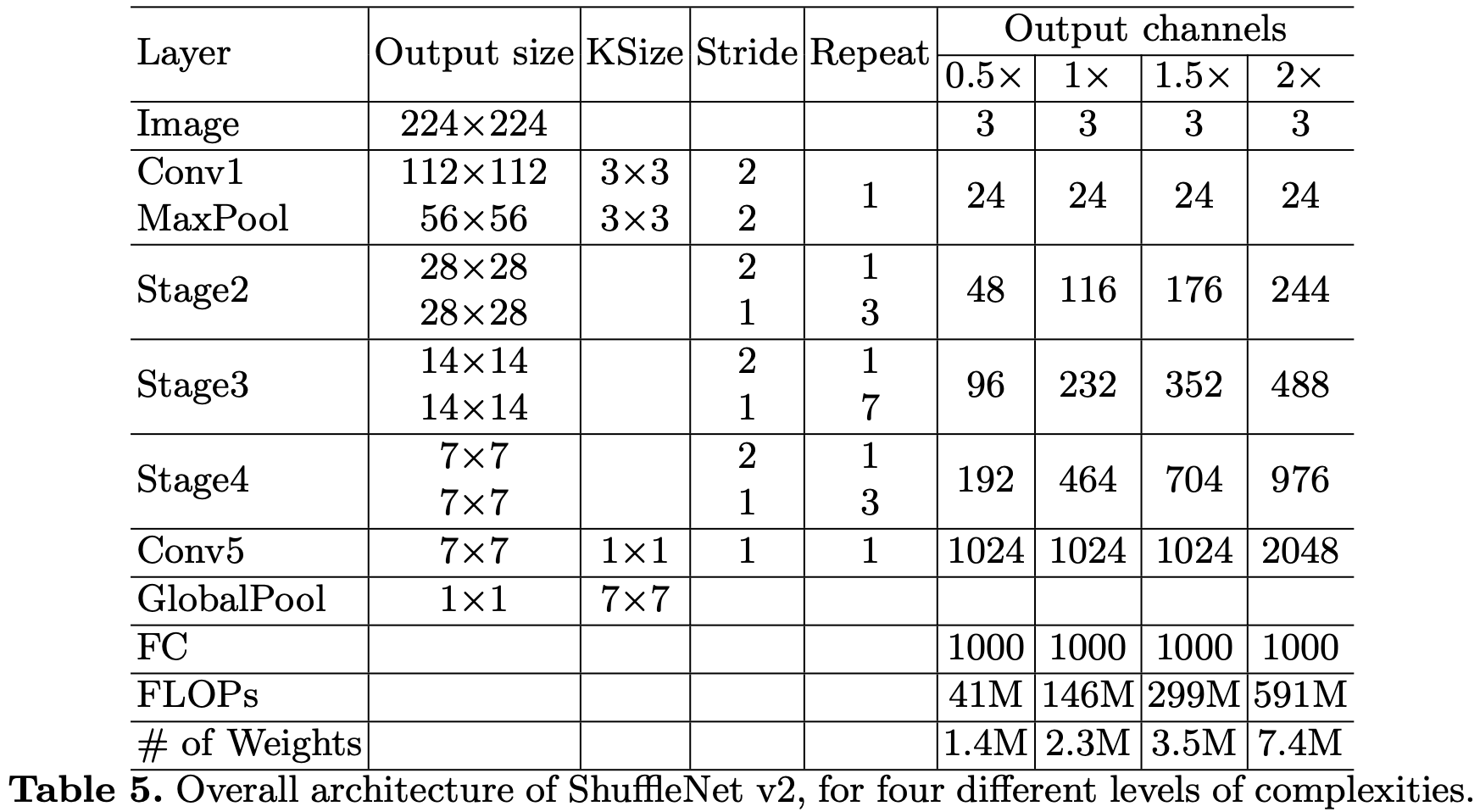
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!