图像文字识别(连载中)
趁着封校,把之前做过的一些项目整理下。这次整下图像文字识别,除了常规的文本检测、字符识别算法,还把之前提出的一种格式化抽取算法也集成了进来,优势是识别大段文字时会按段落合并,并且对于复杂的表格(带有行列融合的)也能按其格式抽取。
所有模型评估均是将其预训练固化后直接调用固化模型,
实验环境:
MacOS 12.3
2.2 GHz 六核Intel Core i7
pytorch
正文
图像文字识别分为两步,一步是文本检测,一步是文字识别。分开来说
文本检测
文本检测即在图像中检测出哪存在文本,从而将本文从复杂背景中分割出来,方便后续的文字识别。
传统的文本检测方法一般采用手工特征提取的方式进行检测文本,比如 SWT、MSER等方法,然后采用模板匹配或模型训练的方法对检测到的文本进行识别。而现在的深度学习方法使用卷积神经网络代替手工提取特征方法进行文本检测,然后神经网络对检测到的文本进行识别。本文也主要介绍基于深度神经网络的文本检测与文本识别方法。
文本检测也属于目标检测的一个小类,但又与传统的目标检测不一样。
传统的目标检测方法如Faster-RCNN系列、Yolo系列、SSD等在普通物体上的目标检测效果很好。但直接应用于文本检测效果还是不太理想,主要原因如下:
- 文本大多数以长矩形形式存在,与普通的目标检测中的物体不一样(长宽比接近于1)。
- 普通物体存在明显的闭合边缘轮廓,而文本没有。
- 文本中包含多个文字,而文字之间是有间隔的,如果检测做的不好,我们就会把每个字都当成文本行给框出来而非整行作为文本框,这与我们的期望不一样。
因此现有的很多文本检测方法其实基于已有的目标检测方法对于文本特性进行改进得来。
CTPN(Detecting Text in Natural Image with Connectionist Text Proposal Network)
创新与出发点
- 文本检测和一般目标检测的不同:文本线是一个sequence(字符、字符的一部分、多字符组成的一个sequence),而不是一般目标检测中只有一个独立的目标。这既是优势,也是难点。优势体现在同一文本线上不同字符可以互相利用上下文,可以用sequence的方法比如RNN来表示。难点体现在要检测出一个完整的文本线,同一文本线上不同字符可能差异大,距离远,要作为一个整体检测出来难度比单个目标更大——因此,作者认为预测文本的竖直位置(文本bounding box的上下边界)比水平位置(文本bounding box的左右边界)更容易。
- Top-down(先检测文本区域,再找出文本线)的文本检测方法比传统的bottom-up的检测方法(先检测字符,再串成文本线)更好。自底向上的方法的缺点在于(这点在作者的另一篇文章中说的更清楚),总结起来就是没有考虑上下文,不够鲁棒,系统需要太多子模块,太复杂且误差逐步积累,性能受限。
- RNN和CNN的无缝结合可以提高检测精度。CNN用来提取深度特征,RNN用来序列的特征识别(2类),二者无缝结合,用在检测上性能更好
方法概括
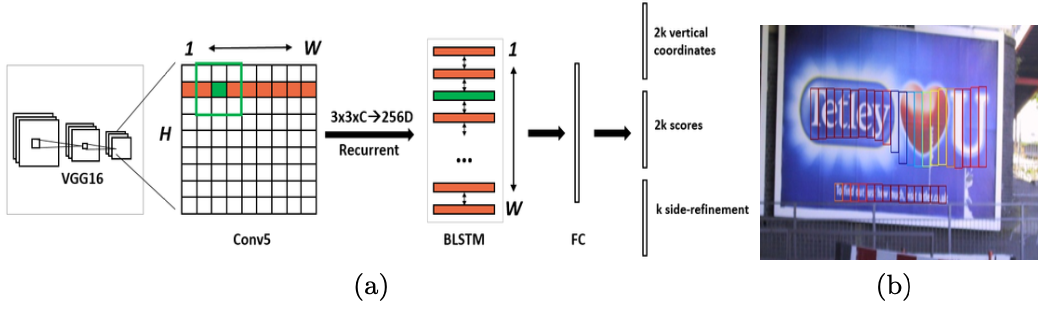
其基本流程如上图
- 第一,用VGG16的前5个Conv stage(到conv5)得到feature map(WHC)
- 第二,在Conv5的feature map的每个位置上取33C的窗口的特征,这些特征将用于预测该位置k个anchor(anchor的定义和Faster RCNN类似)对应的类别信息,位置信息。
- 第三,将每一行的所有窗口对应的33C的特征(W33C)输入到RNN(BLSTM)中,得到W256的输出
- 第四,将RNN的W*256输入到512维的fc层
- 第五,fc层特征输入到三个分类或者回归层中。第二个2k scores 表示的是k个anchor的类别信息(是字符或不是字符)。第一个2k vertical coordinate和第三个k side-refinement是用来回归k个anchor的位置信息。2k vertical coordinate表示的是bounding box的高度和中心的y轴坐标(可以决定上下边界),k个side-refinement表示的bounding box的水平平移量。这边注意,只用了3个参数表示回归的bounding box,因为这里默认了每个anchor的width是16,且不再变化(VGG16的conv5的stride是16)。回归出来的box如Fig.1中那些红色的细长矩形,它们的宽度是一定的。
- 第六,用简单的文本线构造算法,把分类得到的文字的proposal(图中(b)的细长的矩形)合并成文本线
总结
这篇文章的方法最大亮点在于把RNN引入检测问题(以前一般做识别)。文本检测,先用CNN得到深度特征,然后用固定宽度的anchor来检测text proposal(文本线的一部分),并把同一行anchor对应的特征串成序列,输入到RNN中,最后用全连接层来分类或回归,并将正确的text proposal进行合并成文本线。这种把RNN和CNN无缝结合的方法提高了检测精度。
问:为什么要使用BLSTM
答:CTPN的网络结构与Faster-RCNN类似,只是其中加入了BLSTM层。CNN学习的是感受野内的空间信息;而且伴随网络的深入,CNN学到的特征越来越抽象。对于文本序列检测,显然需要CNN学到的抽象空间特征;另外文本所具备的sequence feature(序列特征)也有助于文本检测。对于水平的文本行,其中的每一个文本段之间都是有联系的,因此作者采用了CNN+RNN的一种网络结构,使得检测结果更加鲁棒。
问:如何通过”FC”卷积层输出产生Text proposals?
答:CTPN通过CNN和BLSTM学到一组“空间 + 序列”特征后,在”FC”卷积层后接入RPN网络。这里的RPN与Faster R-CNN类似,分为两个分支:
- 左边分支用于bounding box regression。由于fc feature map每个点配备了10个Anchor,同时只回归中心y坐标与高度2个值,所以rpn_bboxp_red有20个channels
右边分支用于softmax分类Ancho
问:Anchor为什么这么设置
答:* 保证在x方向上,Anchor 覆盖原图每个点且不相互重叠。- 不同文本在 y方向上高度差距很大,所以设置Anchors高度为11-283,用于覆盖不同高度的文本目标。
源码
固化模型1
耗时
SegLink(Detecting Oriented Text in Natural Images by link Segments)
创新单与出发点
- 提出了文本行检测的两个基本组成元素:segment和link
- 提出了基于SSD的改进版网络结构(全卷积网络结果)同时预测不同尺度的segments和link
- 提出了两种link类型: 层内连接(within-layer link)和跨层连接(cross-layer link)
- 可以处理多方向和任意长度的文本
方法概括
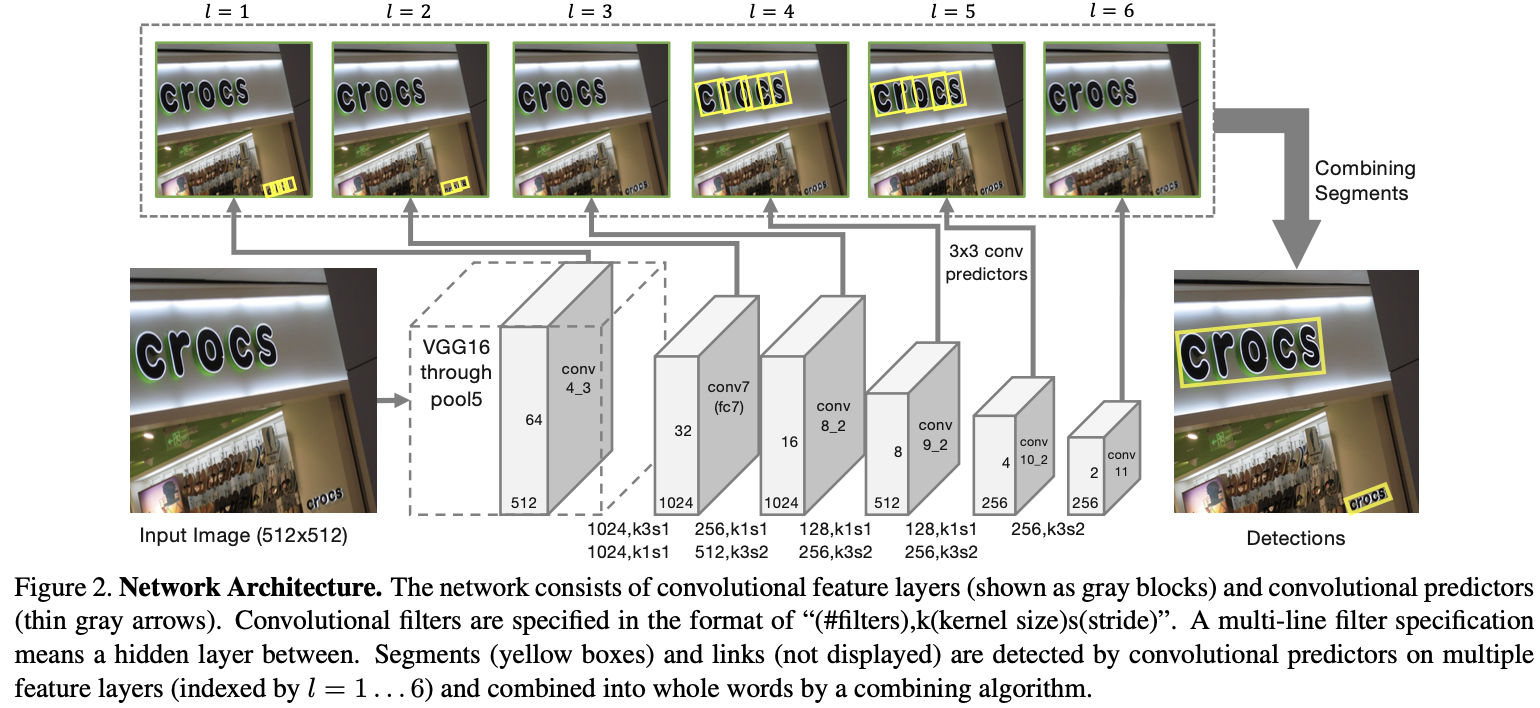
整个实现过程包括两部分:首先检测segments,links,然后使用融合算法得到最终文本行.具体步骤如下:
- 主干网络是沿用了SSD网络结构,并修改修改了最后的Pooling层,将其改为卷积层.具体来说:首先用VGG16作为basenet,并将VGG16的最后两个全连接层改成卷积层.接着增加一些额外的卷积层,用于提取更深的特征,最后的修改SSD的Pooling层,将其改为卷积层
- 提取不同层的feature map,文中提取了conv4_3, conv7, conv8_2, conv9_2, conv10_2, conv11.这里其实操作还是和SSD网络一样
- 对不同层的feature map使用3*3的卷积层产生最终的输出(包括segment和link),不同特征层输出的维度是不一样的,因为除了conv4_3层外,其它层存在跨层的link.这里segment是text的带方向bbox信息(它可能是个单词,也可能是几个字符,总之是文本行的部分),link是不同bbox的连接信息(文章将其也增加到网络中自动学习).
- 然后通过融合规则,将segment的box信息和link信息进行融合,得到最终的文本行.
总结
缺点:不能检测间隔很大的文本行,不能检测弯曲文本
- 与CTPN思想类似,都是先找出文本行的一部分,然后再连接所有的部分,组成一个完整的文本行;
- 在SSD基础上加入了旋转角度的学习;
- 在小部分文本框之前用连接线(相邻框的中点连线)来表示属不属于同一个文本框,也是用网络来学习;
- 使用融合规则将各个阶段的框信息和线信息进行融合,组成文本行。
源码
固化模型1
EAST(EAST: An Efficient and Accurate Scene Text Detector)
贡献
- 只包含两个阶段:全卷积网络(FCN)和非极大值抑制(NMS)。FCN直接产生文本区域,没有冗余和耗时的中间步骤。
- 可以灵活的生成词级或者行级的预测,它们的几何形状可以是旋转框或者四边形。
- 采用了Locality-Aware NMS来对生成的几何进行过滤
- 所提出的算法在精度和速度方面都有所提高
方法概括
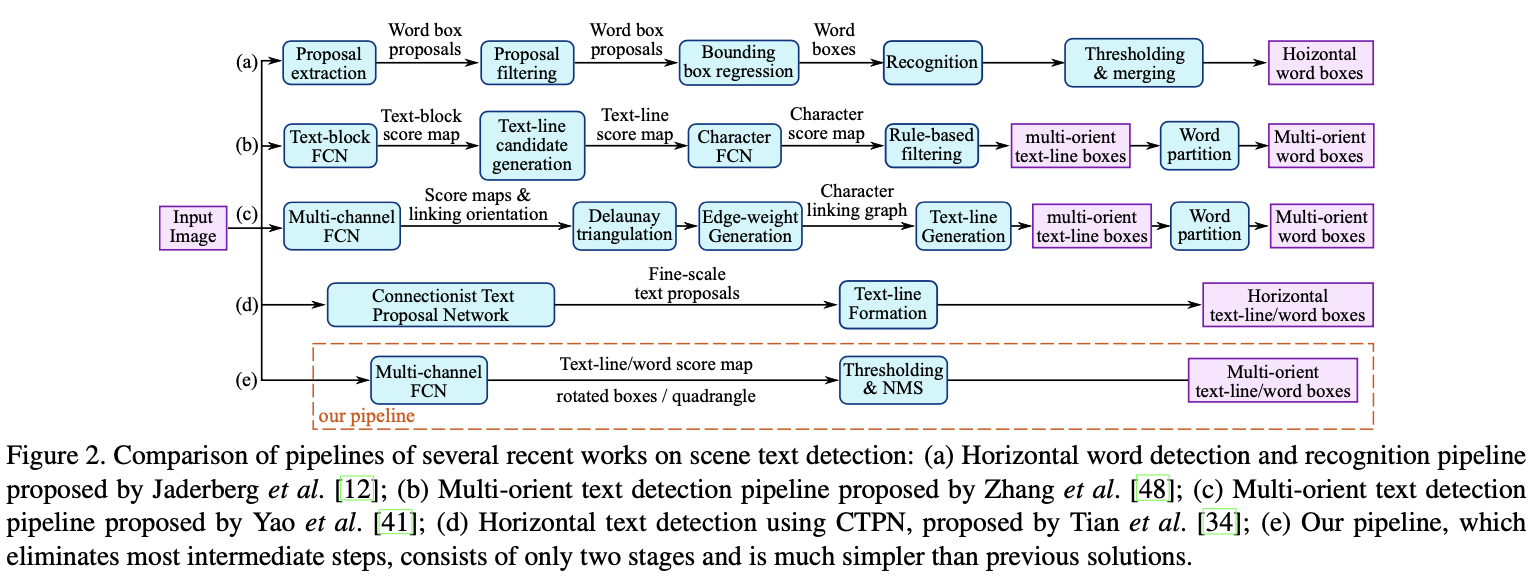
EAST模型的网络结构分为特征提取层、特征融合层、输出层三大部分
- 特征提取层
基于PVANet(一种目标检测的模型)作为网络结构的骨干,分别从stage1,stage2,stage3,stage4的卷积层抽取出特征图,卷积层的尺寸依次减半,但卷积核的数量依次增倍,这是一种“金字塔特征网络”(FPN,feature pyramid network)的思想。通过这种方式,可抽取出不同尺度的特征图,以实现对不同尺度文本行的检测(大的feature map擅长检测小物体,小的feature map擅长检测大物体)。这个思想与SegLink模型很像; - 特征融合层
将前面抽取的特征图按一定的规则进行合并,这里的合并规则采用了U-net方法,规则如下:- 特征提取层中抽取的最后一层的特征图(f1)被最先送入unpooling层,将图像放大1倍
- 接着与前一层的特征图(f2)串起来(concatenate)
- 然后依次作卷积核大小为1x1,3x3的卷积
- 对f3,f4重复以上过程,而卷积核的个数逐层递减,依次为128,64,32
- 最后经过32核,3x3卷积后将结果输出到“输出层”
- 输出层
最终输出以下四部分的信息,分别是- score map:检测框的置信度,1个参数;
- text boxes:检测框的位置(x, y, w, h),4个参数;
- text rotation angle:检测框的旋转角度,1个参数;
- text quadrangle coordinates:任意四边形检测框的位置坐标,(x1, y1), (x2, y2), (x3, y3), (x4, y4),8个参数。
其中,text boxes的位置坐标与text quadrangle coordinates的位置坐标看起来似乎有点重复,其实不然,这是为了解决一些扭曲变形文本行
总结
把完整文本行先分割检测再合并的思路,做法比较麻烦,把文本检测切割成多阶段来进行,增大了文本检测精度的损失和时间消耗,中间处理影响效果。(候选框选取,候选框过滤,bbox回归,候选框合并)
- 通过FCN结构的网络直接学习是不是文本框以及文本框的坐标和角度(或者八个坐标);
- 局部感知NMS(先合并再NMS),降低了NMS的复杂度。
- 精度和速度都有所提高
缺点:感受野不大,对于长文本检测不是很好,比较适合短文本行检测
AdvancedEAST:score map -> 文本头部、中部和尾部三部分,没有从根本上解决长文本检测。
源码
固化模型1
PSENet(Shape Robust Text Detection with Progressive Scale Expansion Network)
论文
bbox回归的方法对弯曲文本的检测不准确,分割的方法对文字紧靠的情况分割效果不好。
亮点:渐进式扩展算法
- 是一个基于像素分割的方法,能够精确地定位任意形状的文本实例;
- 提出了渐进式扩展算法,即使两个文本实例离得很近也可以分开,从而保证文本实例的准确位置
从最小尺度的kernels开始扩展,最小的kernels可以把紧靠的文本实例分开;逐渐扩展到更大的kernels;直到扩展到最大的kernels,组成最终的结果。
缺点:对于不同的数据集,超参数的选取较为重要(最小尺度比例和分割结果数)。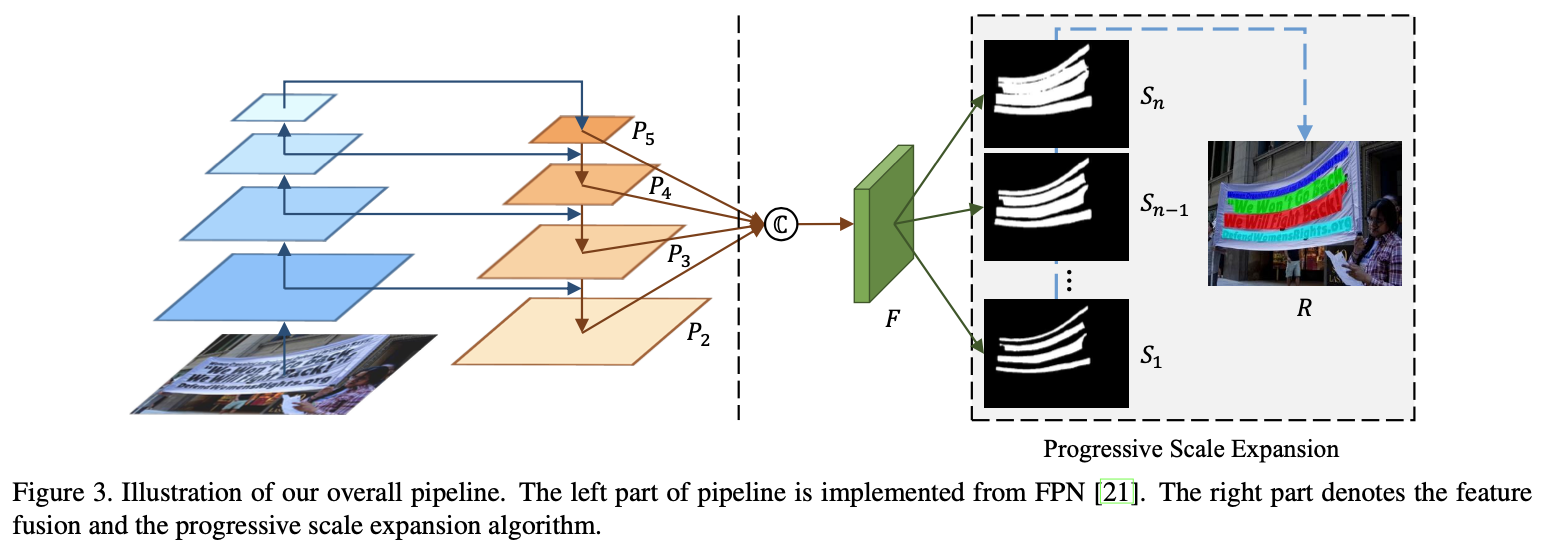
源码
固化模型1
LSAE(Learning Shape-Aware Embedding for Scene Text Detection)
- 分离紧靠的文本实例
- 解决文本行过长的问题
使用输出的三个结果做聚类。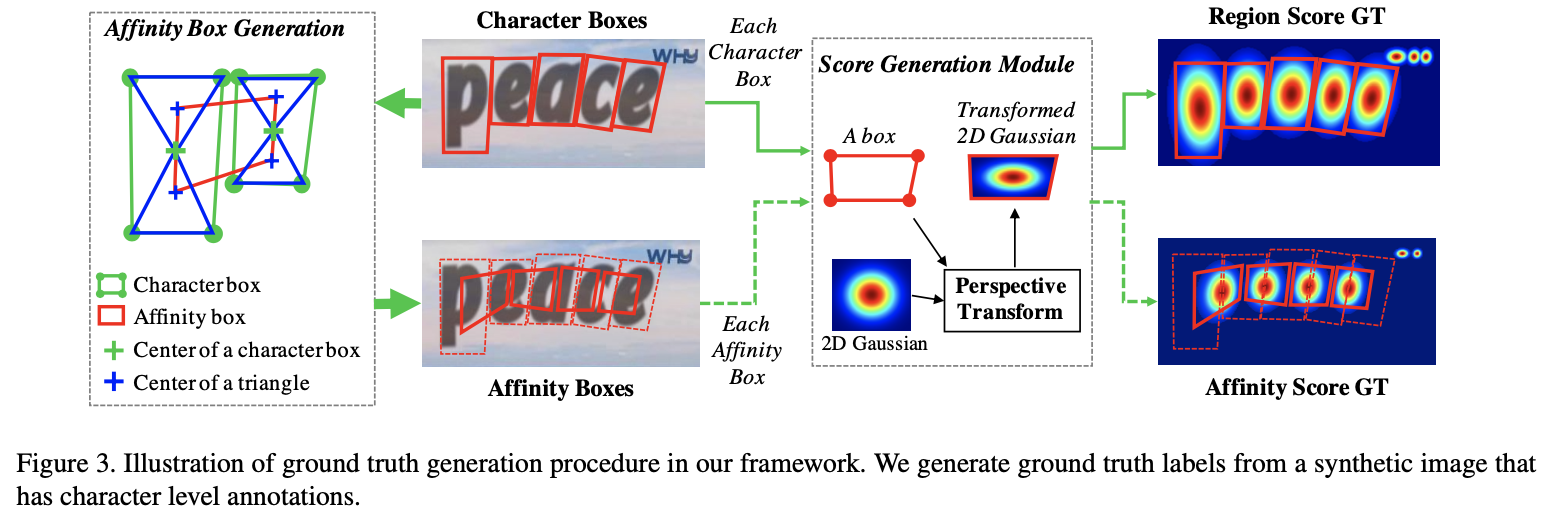
源码
固化模型1
ATRR(Arbitrary Shape Scene Text Detection with Adaptive Text Region Representation)
论文
是一个两阶段的文本检测,第一阶段与Faster R-CNN类似,通过CNN + RPN + ROI 得到 text proposals;第二阶段就是对 text proposals进行细化,使预测的框更加准确。
主干网络使用的是 SE-VGG16(添加了SE block的VGG16),实验证明SE Block可以提升性能。
它的亮点主要是提出了自适应文本区域表示,可以根据文本框的形状使用网络去学习应该使用多少个点来表示文本框,之前的方法都是使用固定的点来表示文本框,但是水平文本、多向文本和弯曲文本的点的个数是不相同的,所以自己学习文本框的点数可以适应各种形状的文本框。实现这个功能的是LSTM,对文本框边界的上边框和下边框的对点进行回归,并且用 continue/stop标签来表示对点的结束标志。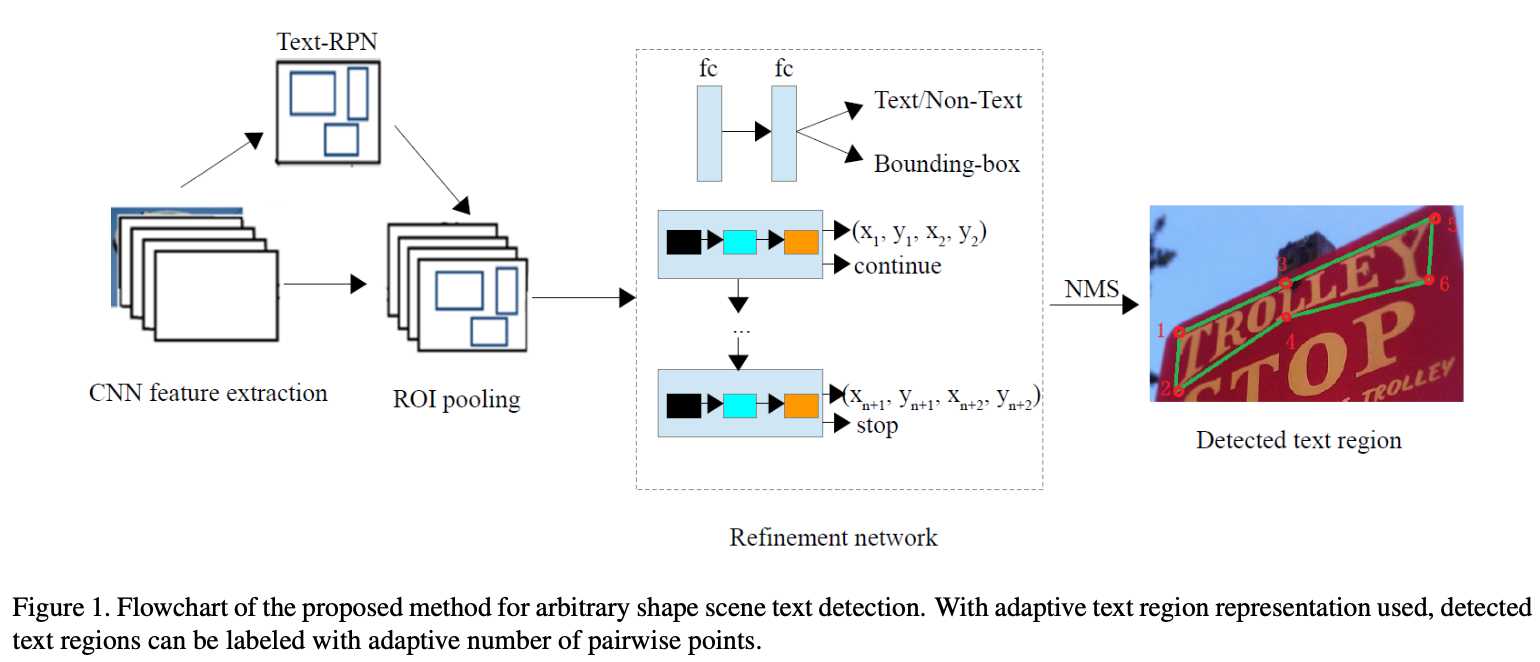
流程
训练:
- 输入图像,使用SE-VGG16提取 feature maps;
- 生成anchor,大小 { 32 , 64 , 128 , 512 } {32, 64, 128, 512} {32,64,128,512} ,纵横比 { 0.5 , 1 , 2 } {0.5, 1, 2} {0.5,1,2};
- 使用RPN网络和ROI生成 text proposals;
- 通过细化网络验证和微调 text proposals(文本/非文本分类,边框回归,自适应文本区域表示的LSTM)。
预测:
- 输入图像,使用SE-VGG16提取feature maps;
- 使用RON网络和ROI生成text proposals;
- 通过细化网络验证和微调 text proposals;
- 使用多边形NMS得到最后的预测输出。
CRAFT(Character Region Awareness for Text Detection)
论文
提出了一种基于 字符感知 的文本检测方法。该方法是通过精确地定位每一个字符,然后再把检测到的字符连接成一个文本达到检测的目的。由于该方法只需要关注字符以及字符之间的距离,不需要关注整行文本,所以不需要很大的感受野,对于弯曲、变形或者极长的文本都适用。由于要精确的检测到每一个字符,所以对粘连字符(比如孟加拉语和阿拉伯语)的检测效果并不是很好。
在网络结构方面,使用的是VGG16-BN以及类似于 U-net 的结构,最终输出两个通道的 score map: region score 和 affinity score(见上图)。region score表示该像素是字符中心的概率,affinity score 表示相邻字符中间空白区域中心的概率。根据这两个score map将字符连接成文本。
通过精确的定位每一个字符,然后再把检测到的字符连接成一个文本。
- 生成两部分GT,字符框 + 亲和框(同一文本框中的相邻字符),使用高斯热图
- 字符感知方法,只需要很小的感受野就可以了处理长的弯曲文本
流程
训练:
- 首先使用合成数据集训练 50K 个迭代(图2蓝线流程),然后采用每个基准数据集微调模型;
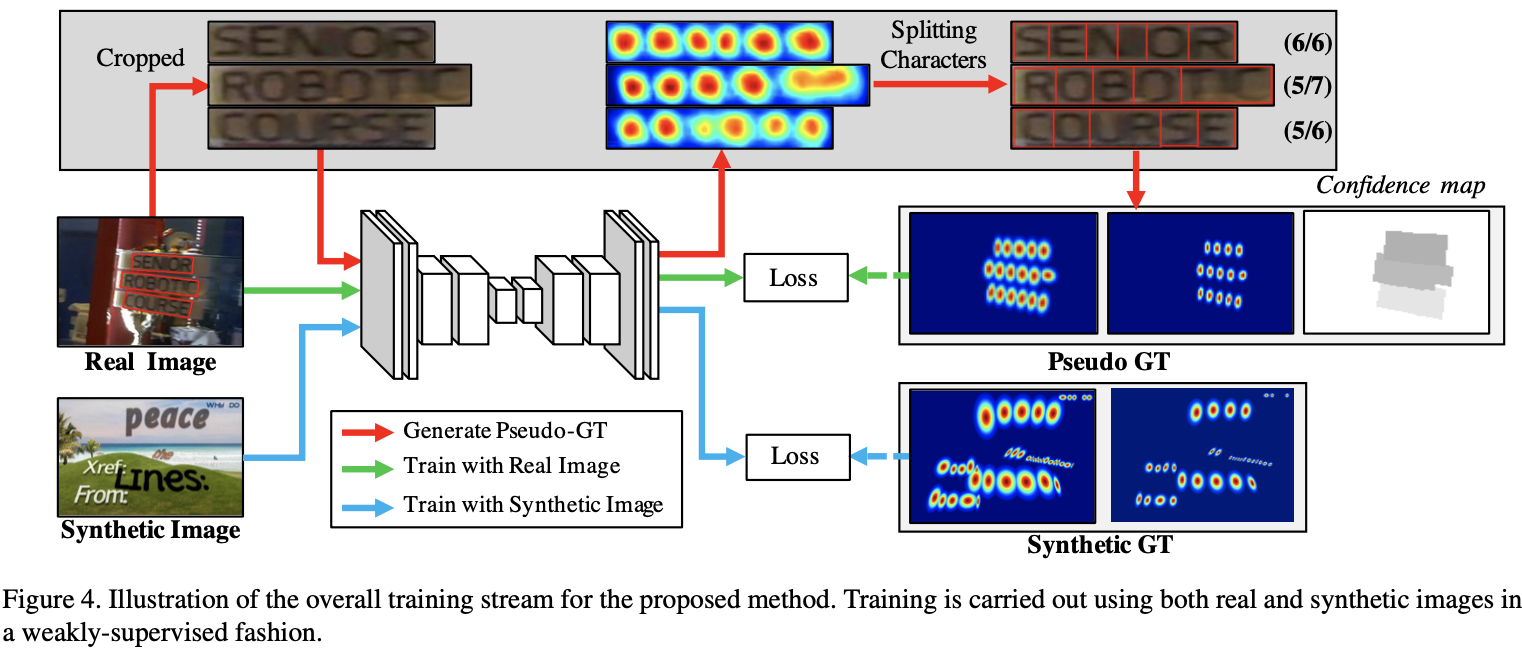
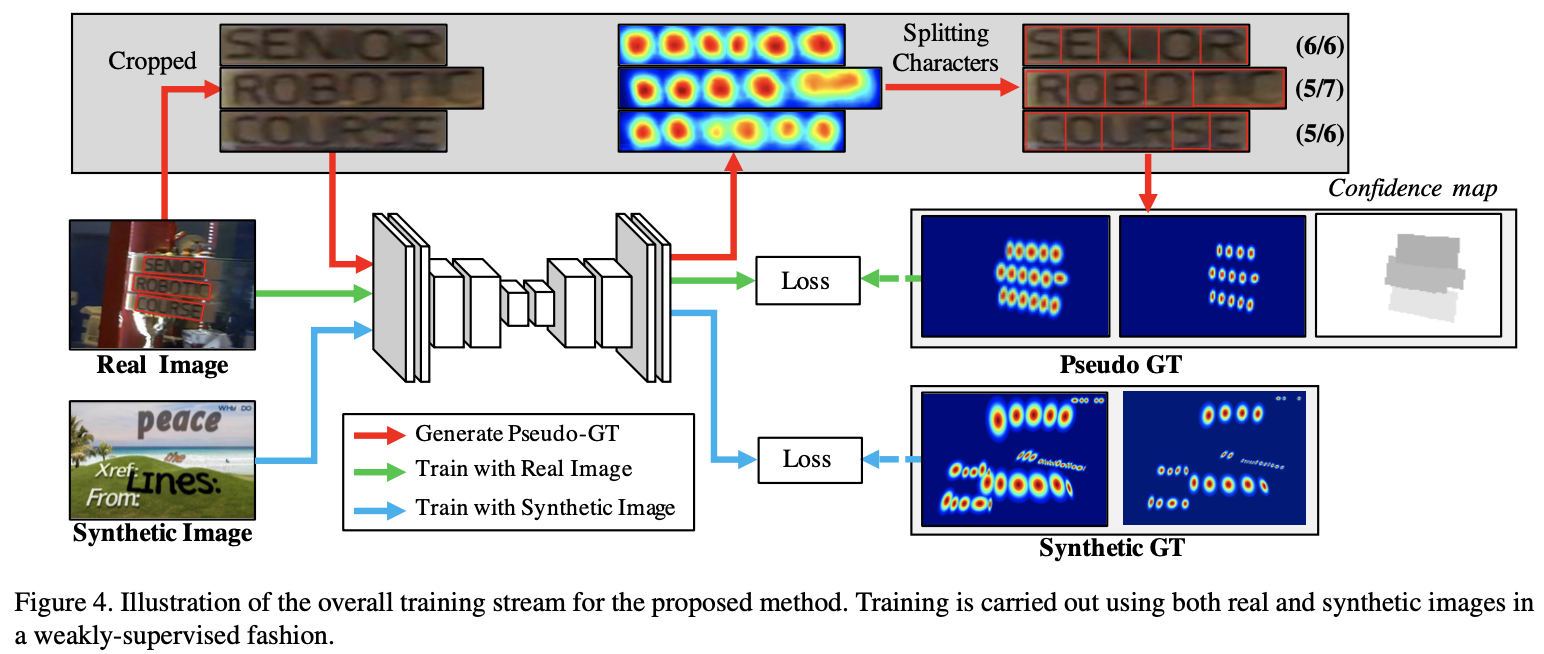
- 对于实际数据集,首先使用 弱监督学习 生成 伪GTs(图2红线流程),然后进行与合成数据相同的训练;
推断:
- 使用训练好的模型生成字符的 region score 和 affinity score;
- 使用文本提出的后处理方法生成文本边框;
- 围绕字符区域生成多边形;
- 对于 CTW-1500 数据集,添加了一个 LinkRefiner 去细化 affinity score,生成了 refined affinity score 来替代 affinity score ,然后再生成多边形。
LOMO(Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes)
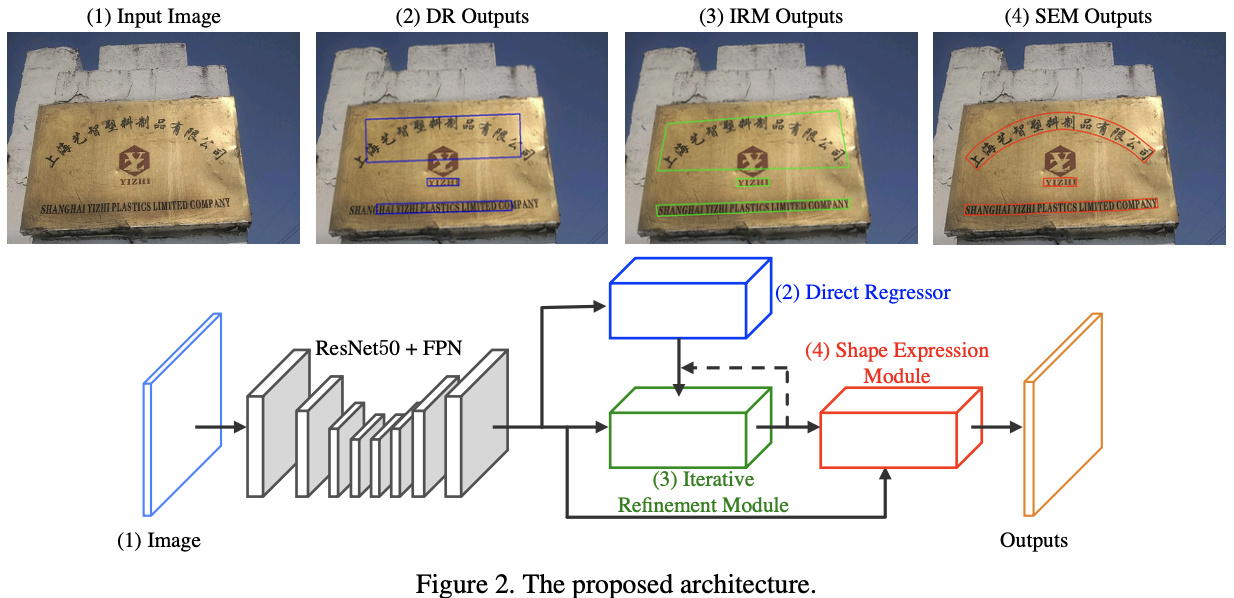
LOMO由直接回归器(DR),迭代优化模块(IRM)和形状表示模块(SEM)组成。
首先,DR分支生成四边形形式的文本建议框。 接下来,IRM基于提取的初步建议功能块,通过迭代细化逐步感知整个长文本。 最后,通过考虑文本实例的几何属性(包括文本区域,文本中心线和边界偏移),引入了SEM来重构不规则文本的更精确表示。
贡献
- 提出了一种迭代优化模块,可以提高长的场景文本检测的性能;
- 引入实例级形状表达模块,以解决检测任意形状的场景文本的问题;
- 具有迭代细化和形状表达模块的 LOMO 可以以端到端的方式进行训练,并在多个基准(包括不同形式(定向,长,多语言和弯曲)的文本实例)上达到最先进的性能
PAN(Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network)
论文
有低计算成本的分割部分和可学习的后处理。分割分割部分由特征金字塔增强模块(FPEM)和特征融合模块(FFM)组成。 FPEM是可级联的U形模块,可以引入多级信息来指导更好的分割。 FFM可以将不同深度的FPEM提供的特征收集到最终特征中进行分割。 可学习的后处理是通过像素聚合(PA)实施的,该算法可以通过预测的相似度矢量精确地聚合文本像素。
- 通过分割网络预测文本区域,内核和相似度向量。FPEM + FFM
- 从预测的内核重建完整的文本实例。
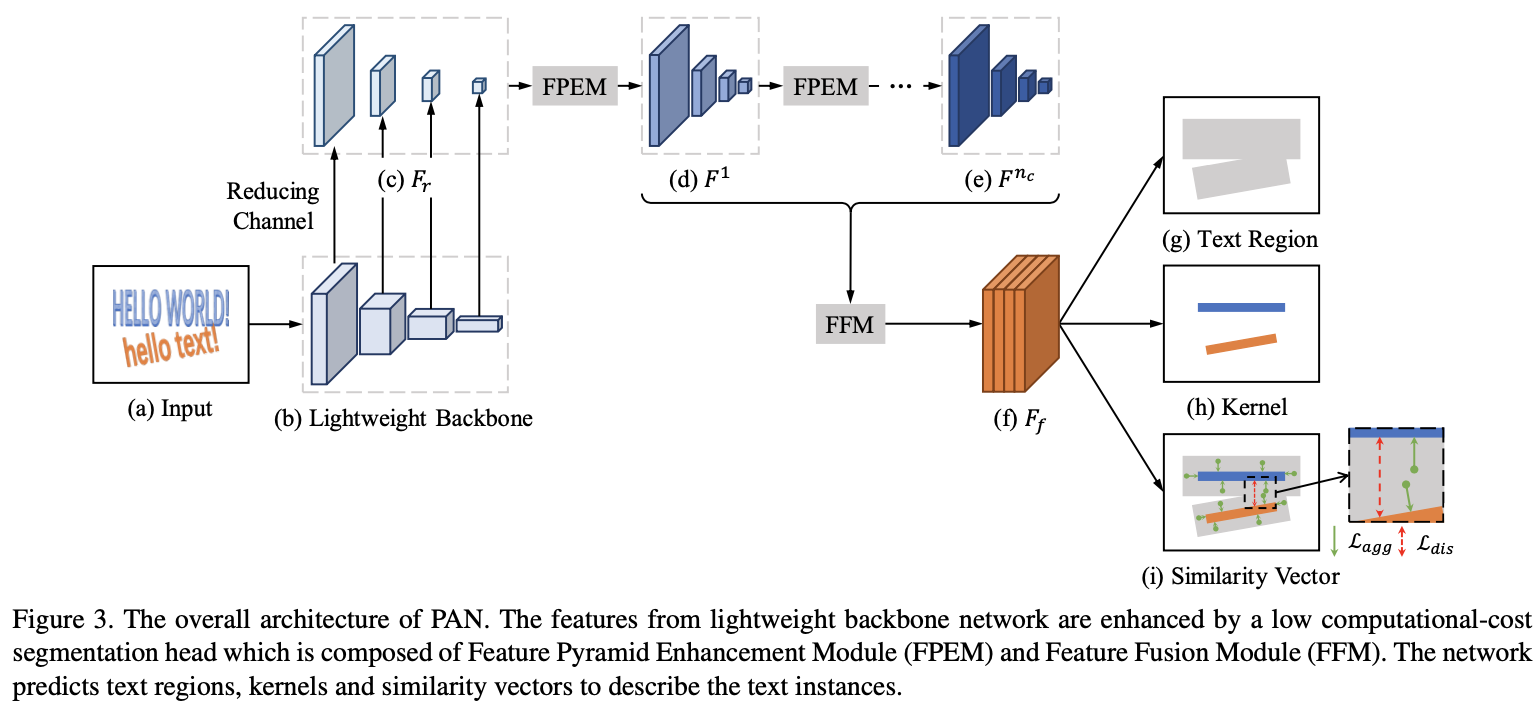
贡献
- 提出了一个轻量级的分割部分,它由特征金字塔增强模块(FPEM)和特征融合模块(FFM)组成,这是两个可以改善网络特征表示的高效模块。
- 提出像素聚合(PA),其中文本相似性矢量可以通过网络学习,并用于选择性地聚合文本内核附近的像素。
- 提出的方法在两个弯曲的文本基准上达到了最先进的性能,同时仍保持了58 FPS的推理速度。
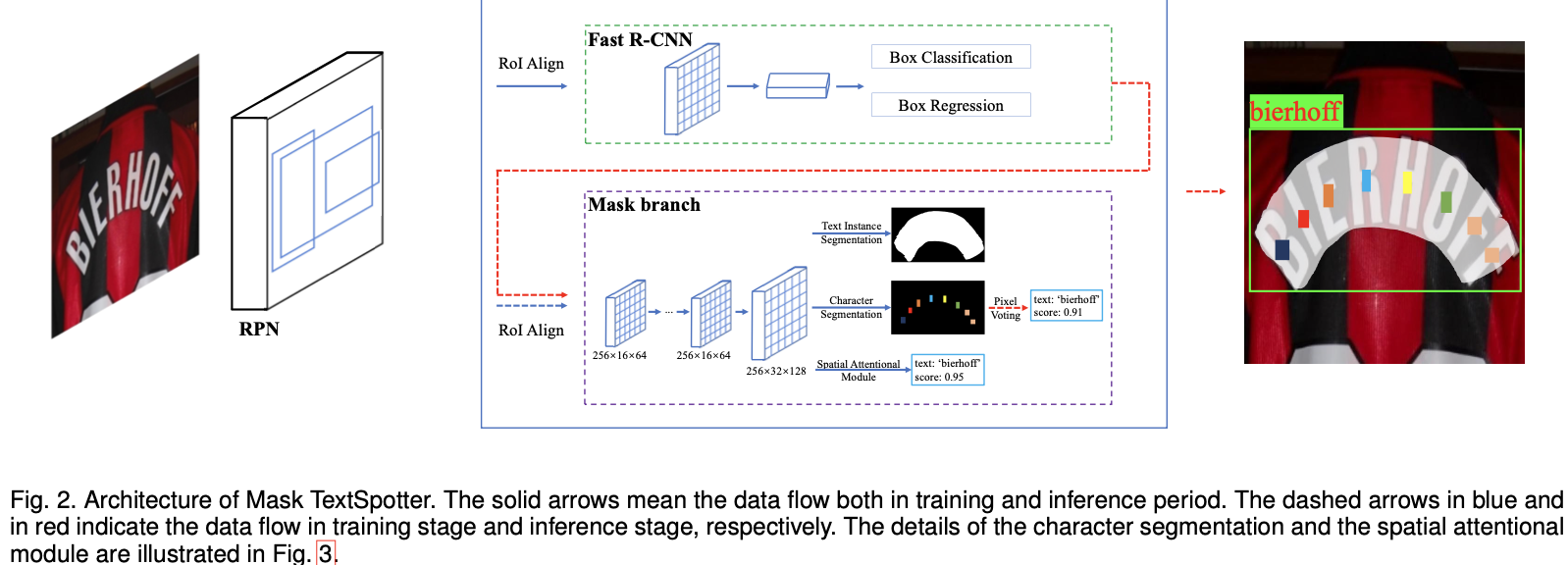
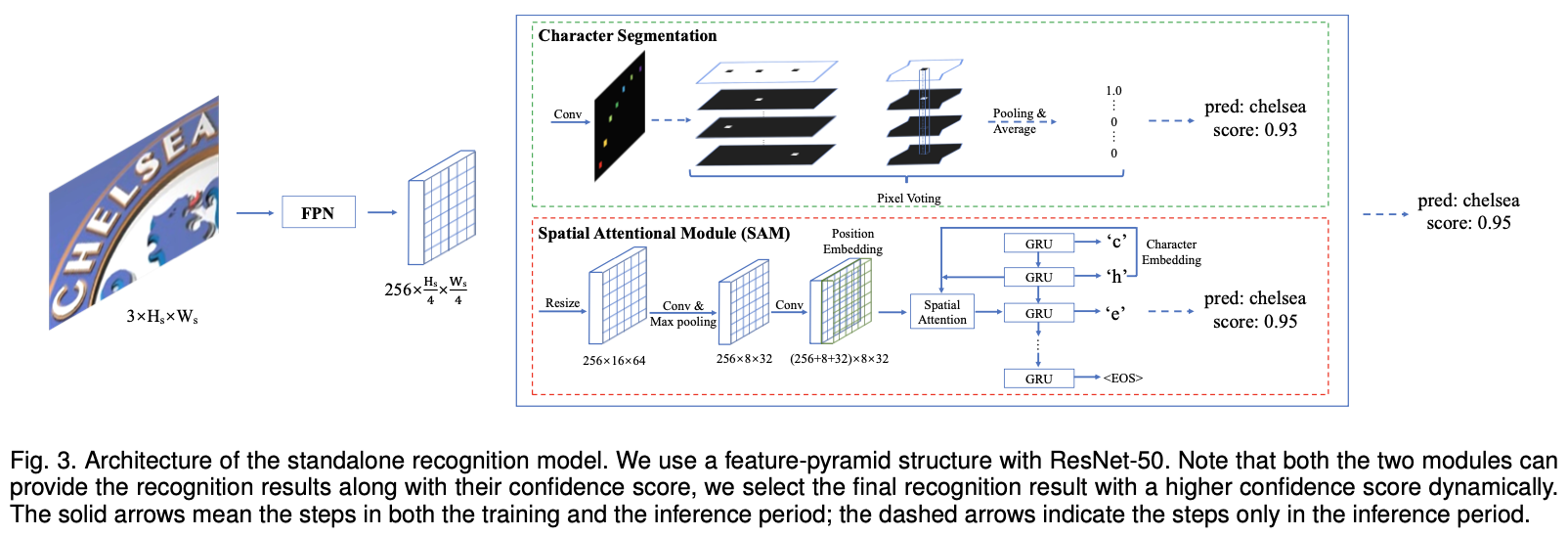
Mask TextSpotter( An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes)
论文
通过语义分割可以直接从二维空间实现检测和识别。
Spatial Attention Module(SAM)
- Mask TextSpotter 的识别模型对于处理二维空间中的常规文本和不规则文本更通用,并且同时考虑本地和全局文本信息会更有效
- 不同于之前的方法只能处理水平或者旋转文本,本文方法可以处理任意形状的文本
- Mask TextSpotter 是第一个完全可端到端训练以进行文本发现的框架,它具有简单,平滑的训练方案,因此其检测模型和识别模型可充分受益于特征共享和联合优化。
Learning to Predict More Accurate Text Instances for Scene Text Detection
论文
为检测弯曲文本,提出与起始顶点无关的坐标回归,提出文本实例精度损失作为辅助任务来细化预测坐标。
基于回归+像素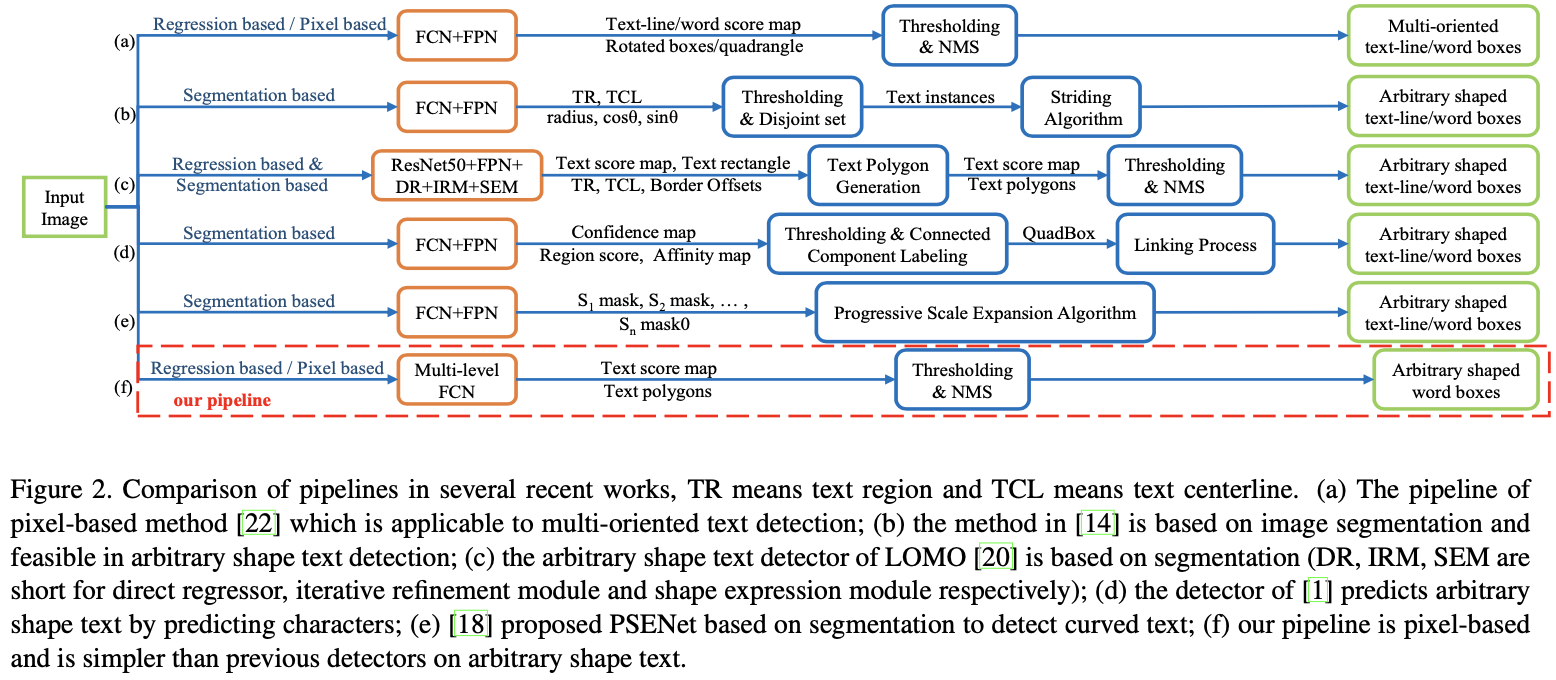
贡献
- 提出了与起点无关的回归损失,而不是传统的回归损失,以优化文本实例的预测坐标,并且与基于分割的方法不同,可以直接优化多边形的坐标。
- 引入文本实例精度损失来获得具有更大IoU的文本多边形,从而在不增加网络计算的情况下进一步提高了性能。
- 提出了一种简单有效的基于像素的方法,该方法仅使用NMS后处理步骤。 该方法可用于无需附加标注的任意形状文本检测,并在Total-Text数据集上获得最新性能
DBNet(Real-time Scene Text Detection with Differentiable Binarization)
论文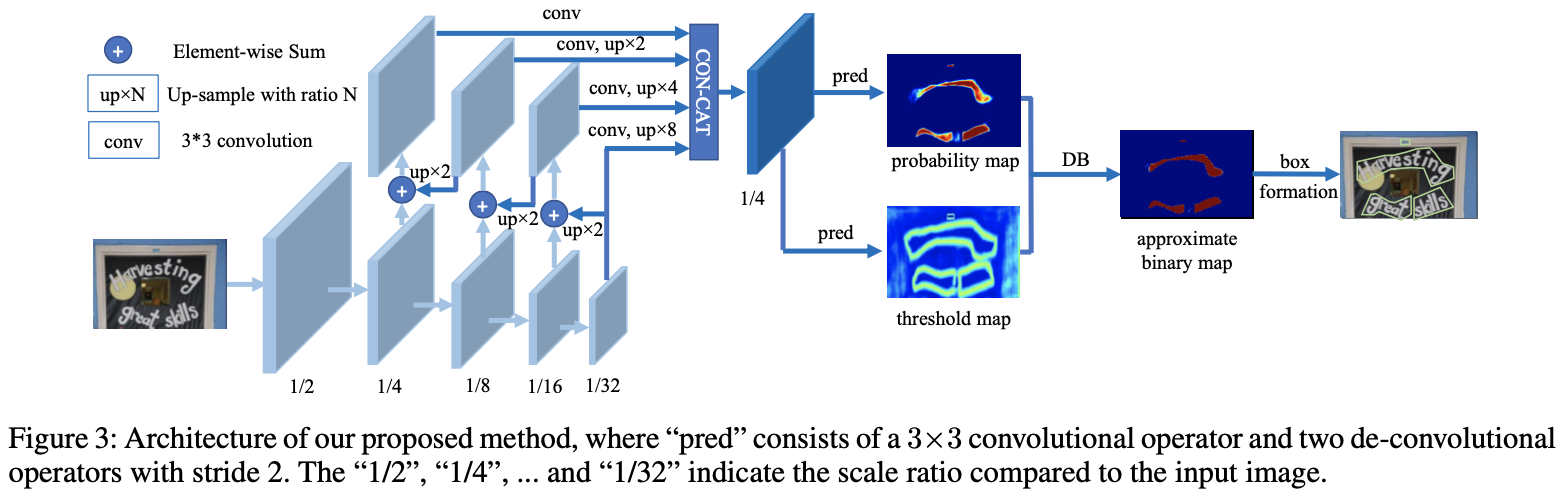
速度很快!
传统的基于分割的文本检测的后处理方法比较复杂,提出的差分二值化不仅可以简化后处理还可以增强文本检测的性能。
- 在5个基准集上实现了比较好的表现
- 比先前的方法更快,DB可以提供一个二值化图,简化了后处理
- 使用轻量级的主干也可以表现好,在ResNet-18主干网络上增强了检测性能
- 在推理阶段,可以移除DB,不影响性能
SBD(Exploring the Capacity of Sequential-free Box Discretization Network for Omnidirectional Scene Text Detection)
论文
SBD首先将四边形边框离散为几个关键边缘,其中包含所有可能的水平和垂直位置。为了解码准确的顶点位置,提出了一种简单而有效的匹配程序来重构四边形边界框。
基本思想是利用与标签序列无关的不变表示形式(例如,最小x,最小y,最大x,最大y,平均中心点和对角线的相交点)来反推边界框坐标。为了简化参数化,SBD首先查找所有包含顶点的离散水平和垂直边。 然后学习序列标记匹配类型以找出最佳拟合的四边形。 摆脱了训练目标的模糊性。
{kind=link}
贡献
- 第一个根据四边形边界框的顺序解决文本检测歧义的方法,这对于实现良好的检测精度至关重要
- 方法的灵活性使其可以利用几个关键的改进,这些改进对于进一步提高准确性至关重要。 我们的方法在各种场景文本基准(包括ICDAR 2015 和MLT)上均达到了最先进的性能。 此外,我们的方法在最近的 ICDAR2019 Robust Reading Challenge on Reading Chinese Text on Signboard 中赢得了文本检测任务的冠军
- 方法经过有效的改进,也可以推广到航空图像中的船舶检测。 TIoU-Hmean的显着改进进一步证明了我们方法的鲁棒性。
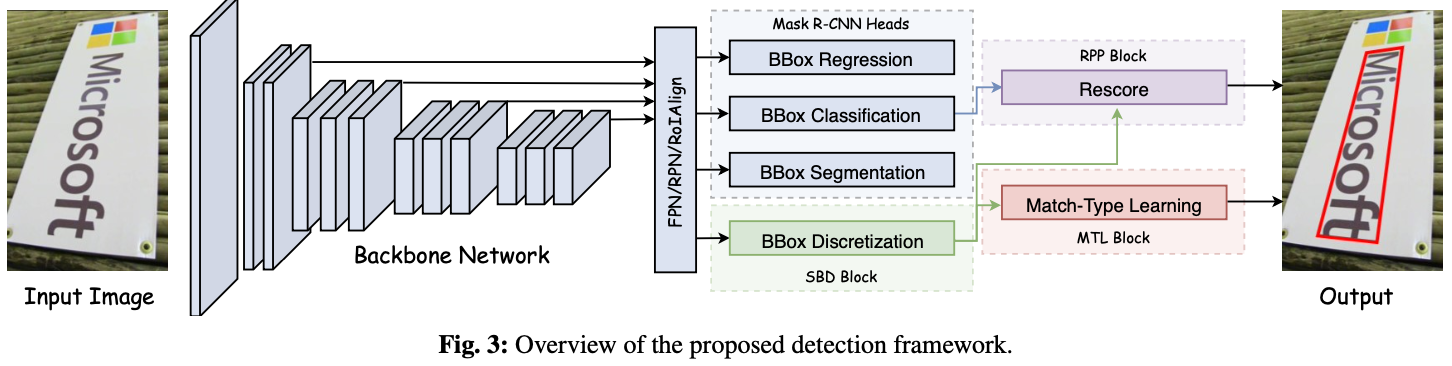
所提出的方法是基于 MaskR-CNN 的。
主要组成:Sequential-free Box Discretization(SBD) + Math-Type Learning(MTL) + Re-scoring and Post Processing(RPP)
检测水平和旋转矩形,不能检测多边形以及任意形状的文本。
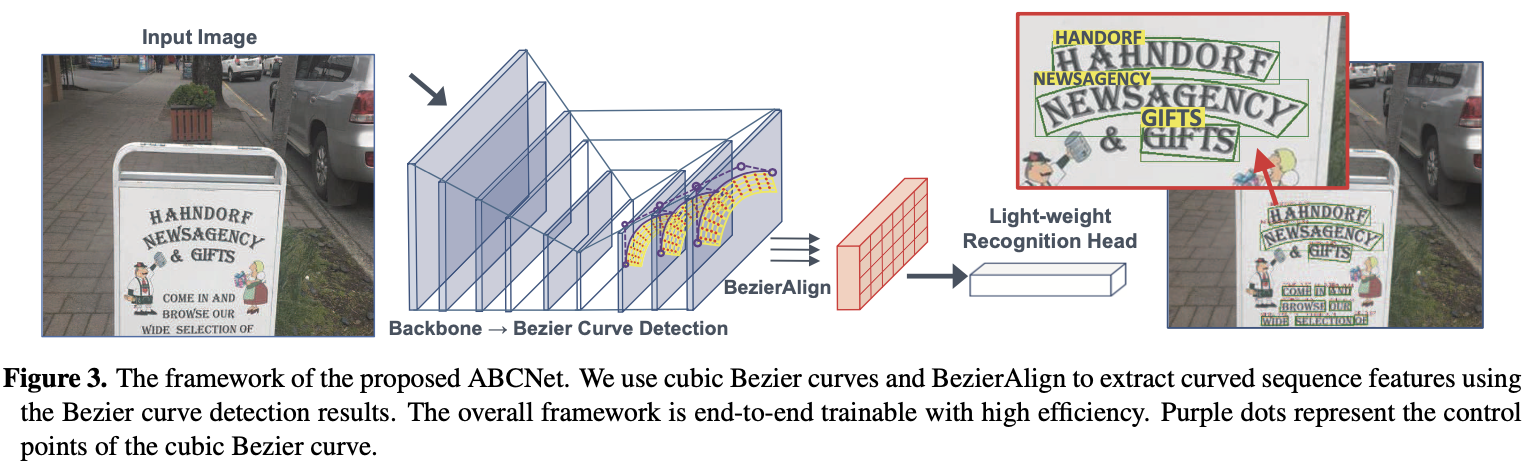
ABCNet(Real-time Scene Text Spotting with Adaptive Bezier-Curve Network)
论文
使用参数化的 Bezier 曲线 自适应的拟合任意形状的文本
贡献
- 基于 FPN 的 Anchor-Free 的文本检测模块,连接检测和识别的采样模块,轻量级的识别模块。
- 使用参数化的 Bezier 曲线 自适应的拟合任意形状的文本
- 为了在图像中准确定位定向的和弯曲的场景文本,首次使用 Bezier 曲线引入了一种新的简洁的弯曲场景文本的参数化表示形式。 与标准边界框表示相比,它引入的计算开销可忽略不计。
- 提出了一种采样方法,也称为 BezierAlign,用于精确的特征对齐,因此识别分支可以自然地连接到整个结构。 通过共享主干特征,可以将识别分支设计为轻型结构。
- 方法的简单性使其可以实时执行推理。 ABCNet 在两个具有挑战性的数据集 Total-Text 和 CTW1500 上实现了最先进的性能,展示了有效性和效率上的优势
SR-Deeptext(Scale robust deep oriented-text detection network)
对文本尺度的变化就有鲁棒性,并且可以减轻类别不平衡。
在EAST基础上做的改动,主干网络使用 ResNet50,不适用多尺度而是在网络中嵌入了上采样层,避免了高计算复杂度。还增加了细化模块 refining block,包含残差卷积单元(RCU)和链式残差池(CRP),以通过使用远程残差连接来改善预测。
FCENet(Fourier Contour Embedding for Arbitrary-Shaped Text Detection)
STKM(Self-attention based Text Knowledge Mining for Text Detection)
MOST: A Multi-Oriented Scene Text Detector with Localization Refinement
TextMountain: Accurate scene text detection via instance segmentation.
TextOCR: Towards large-scale end-to-end reasoning for arbitrary-shaped scene text
STR-TDSL: Scene Text Retrieval via Joint Text Detection and Similarity Learning
TextBPN: Adaptive Boundary Proposal Network for Arbitrary Shape Text Detection
PCR: Progressive Contour Regression for Arbitrary-Shape Scene Text Detection
文字识别
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!