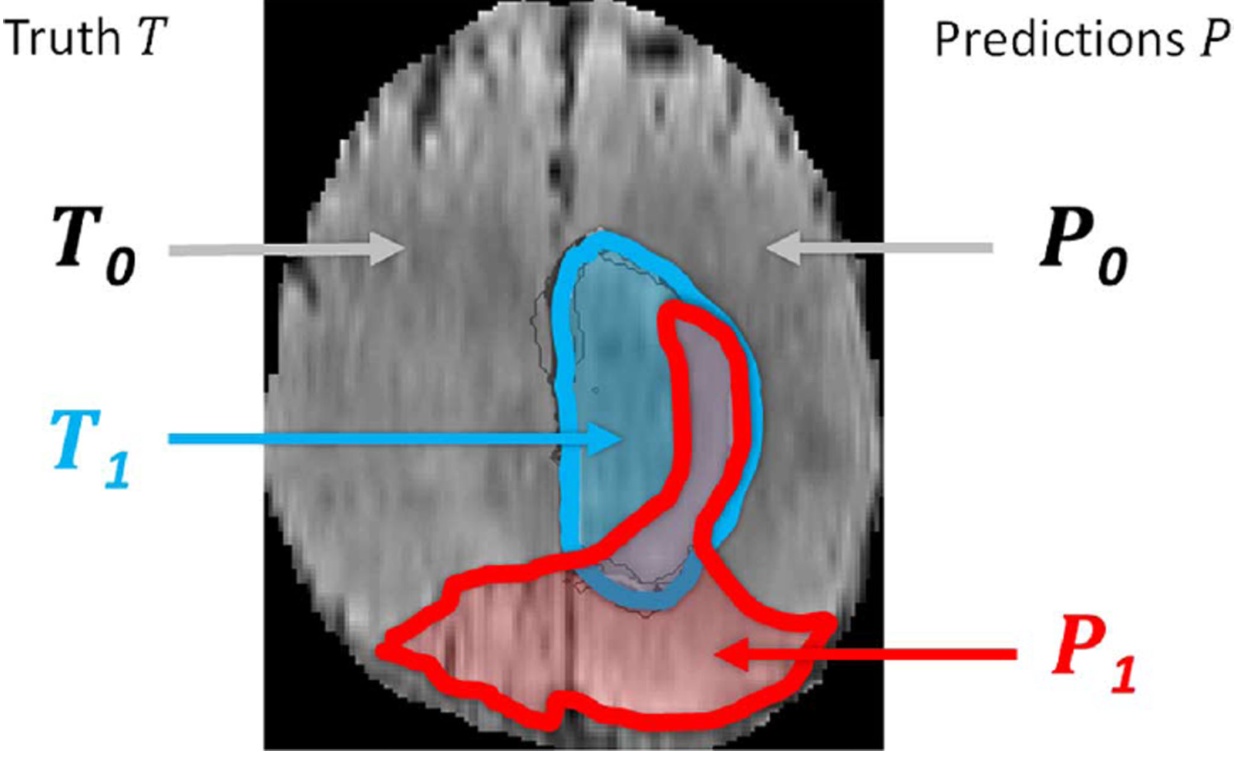
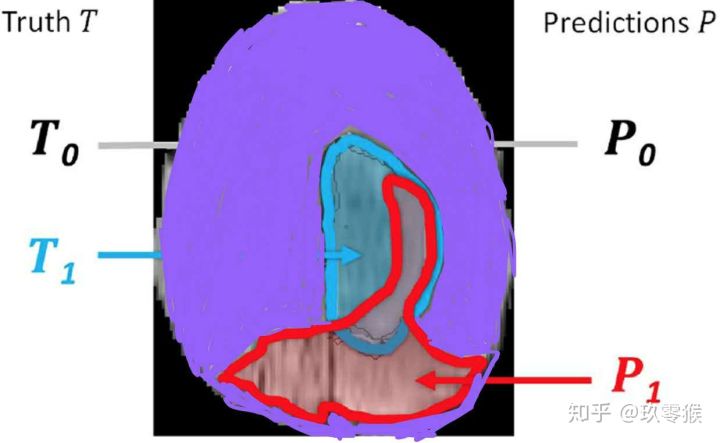
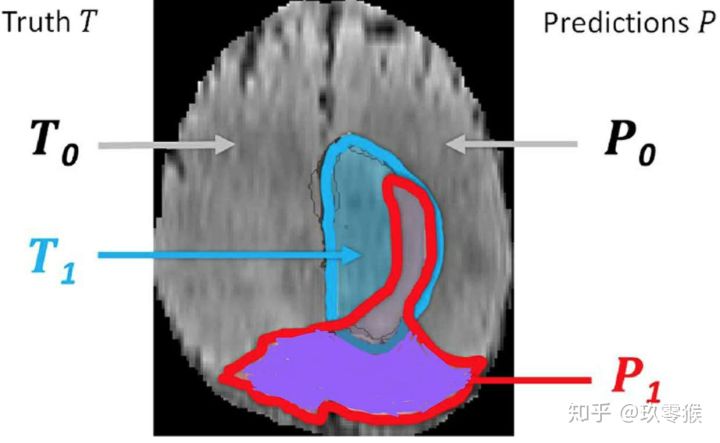
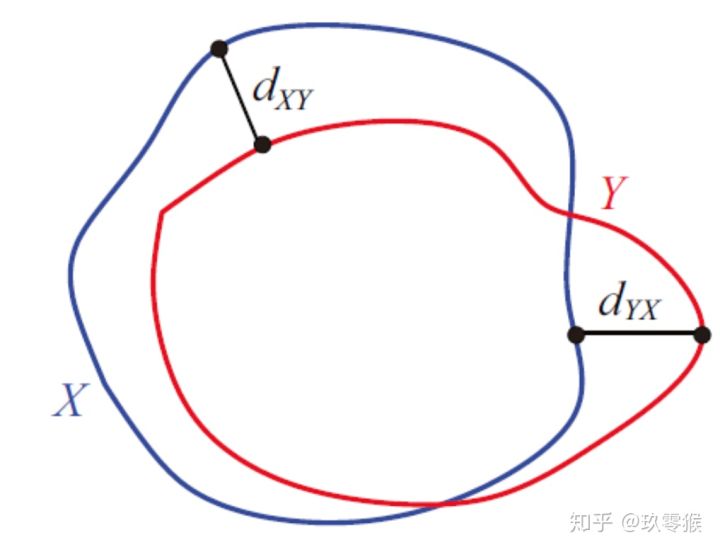
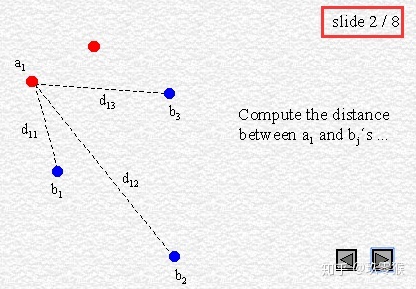
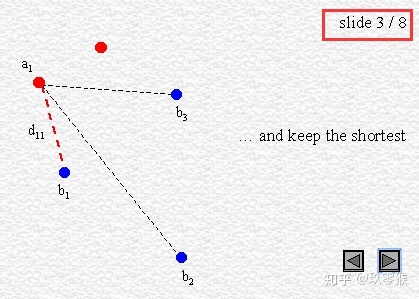
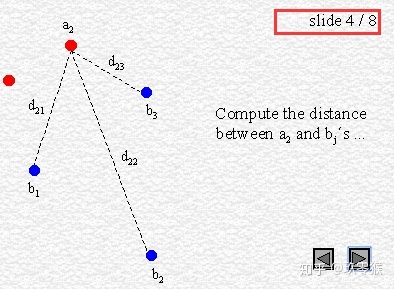
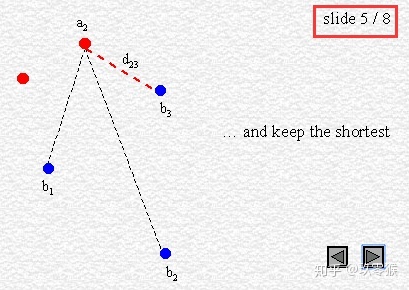
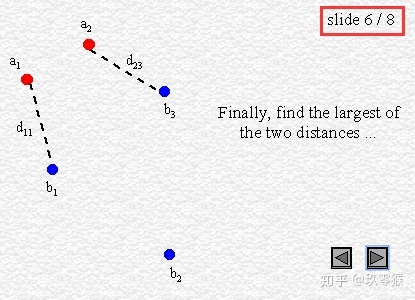
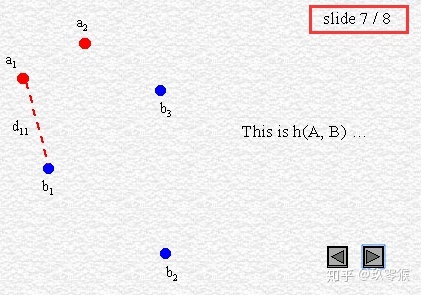
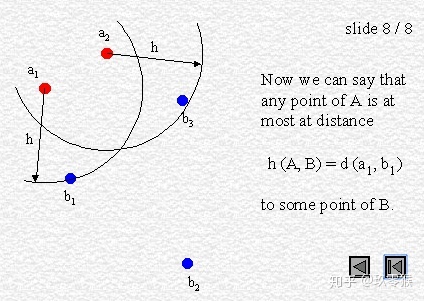
95% HD is similar to maximum HD. However, it is based on the calculation of the 95th percentile of the distances between boundary points in X and Y. The purpose for using this metric is to eliminate the impact of a very small subset of the outliers.
import numpy as np from hausdorff import hausdorff_distance
# two random 2D arrays (second dimension must match) np.random.seed(0) X = np.random.random((1000,100)) Y = np.random.random((5000,100))
# Test computation of Hausdorff distance with different base distances print("Hausdorff distance test: {0}".format( hausdorff_distance(X, Y, distance="manhattan") )) print("Hausdorff distance test: {0}".format( hausdorff_distance(X, Y, distance="euclidean") )) print("Hausdorff distance test: {0}".format( hausdorff_distance(X, Y, distance="chebyshev") )) print("Hausdorff distance test: {0}".format( hausdorff_distance(X, Y, distance="cosine") ))
# For haversine, use 2D lat, lng coordinates defrand_lat_lng(N): lats = np.random.uniform(-90, 90, N) lngs = np.random.uniform(-180, 180, N) return np.stack([lats, lngs], axis=-1)
X = rand_lat_lng(100) Y = rand_lat_lng(250) print("Hausdorff haversine test: {0}".format( hausdorff_distance(X, Y, distance="haversine") ))